FAQ
How do I configure parameters for deployment running?
-
On the Dashboard page, open the console for the workspace you want to manage.
-
In the Console navigation pane, click Deployments.
-
Click the name of the deployment you want to configure. The Deployments working area will be displayed; by default, the Configuration > Basic tab is open.
-
Expand the Parameters tab and click Edit at the righthand end of the tab title bar to access the options for editing.
-
Add the following related configurations to the Other Configuration field. Make sure that a space exists after the colon (:) between each key-value pair.
task.cancellation.timeout: 180s -
In the upper-right corner of the Parameters section, click Save.
For more information, see Modify deployment.
How do I enable GC logs?
On the Deployments page, find the desired deployment and click the name of the deployment. In the upper-right corner of the Parameters section on the Configuration tab, click Edit. Add the following related configurations to the Other Configuration field. Then, click Save.
-
On the Dashboard page, open the console for the workspace you want to manage.
-
In the Console navigation pane, click Deployments.
-
Click the name of the deployment you want to configure. The Deployments working area will be displayed; by default, the Configuration > Basic tab is open.
-
Expand the Parameters tab and click Edit at the righthand end of the tab title bar to access the options for editing.
-
Add the following related configurations to the Other Configuration field. Make sure that a space exists after the colon (:) between each key-value pair.
env.java.opts:>--XX: +PrintGCDetails-XX:+PrintGCDateStamps-Xloggc:/flink/log/gc.log-XX:+UseGCLogFileRotation-XX:NumberOfGCLogFiles=2-XX:GCLogFileSize=50M -
In the upper-right corner of the Parameters section, click Save.
For more information, see Modify deployment.
How do I handle Truststore and Keystore files in Kafka deployments
Scenario: You encountered NoSuchFileException when deploying Kafka clients that reference truststore and keystore files uploaded in the Artifacts section. The error arose when attempting to access these files via specified paths.
Follow these steps to configure your deployment:
- Artifact-fetcher Adjustment: The artifact-fetcher copies "Additional Dependencies" files to the local file system of the JM/TM pods. Reference them using the "file://" schema.
- Path Specification:
Omit the
file://scheme from the path, using Kafka's local file system layer to load the files directly. - Proper Path Usage:
Use
/flink/usrlib/kafka.client.keystore.jksfor the artifact-fetcher downloaded files. - Dependencies: Add truststore/keystore to "Additional Dependencies" to ensure accessibility.
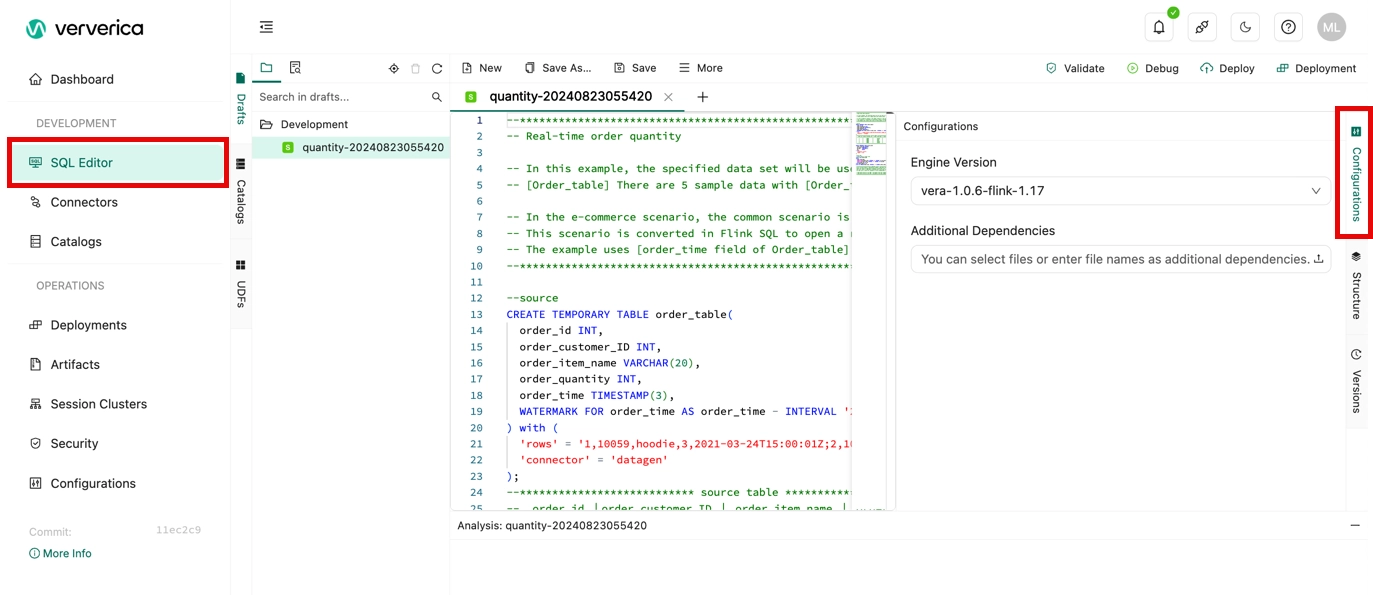
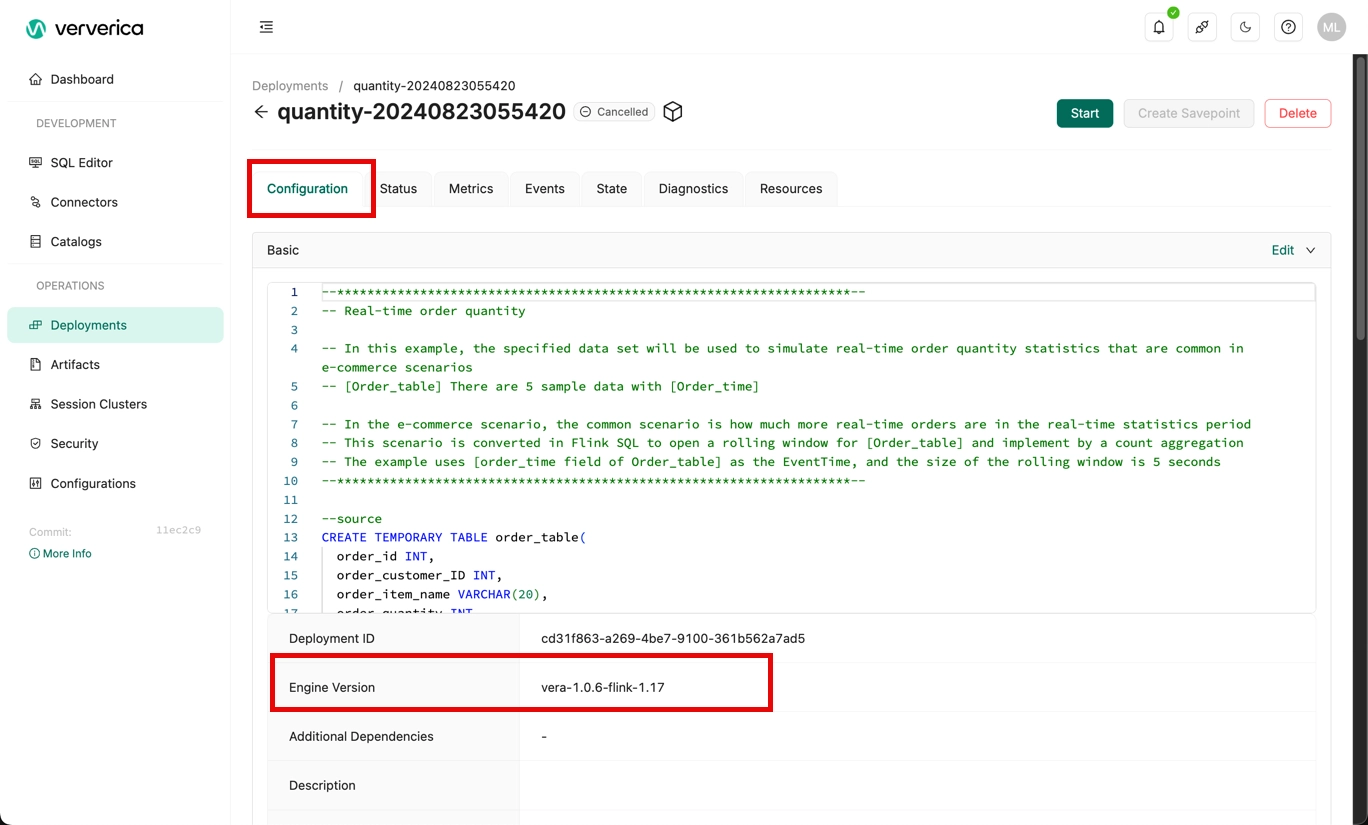
How do I query the engine version of Flink that is used by a deployment?
You can use one of the following methods to view the engine version of Flink that is used by a deployment:
-
On the right side of the SQL Editor page, click the Configurations tab. In the Configurations panel, view the engine version of Flink that is used by a deployment in the Engine Version field.
-
On the Deployments page, click the name of the desired deployment. On the Configuration tab, view the engine version of Flink that is used by a deployment in the Engine Version field of the Basic section.
How do I use the network detection feature in the Ververica Cloud console?
Ververica Cloud supports the network detection feature. To use the network detection feature, perform the following steps in the Ververica Cloud console:
-
On the Dashboard page, open the console for the workspace you want to manage.
-
In the Console navigation pane, click SQL Editor.
-
In the top navigation bar, click the Network detection icon.

-
In the Network detection dialog box, configure the Host parameter to specify an IP address or endpoint to check whether the running environment of a fully managed Flink deployment is connected to the upstream and downstream systems.
If you specify an endpoint, remove :<port> from the end of the endpoint and enter <port> in the Port field in the Network detection dialog box.
How do I troubleshoot dependency conflicts of Flink?
Problem description
- An error caused by an issue in Flink or Hadoop is reported.
java.lang.AbstractMethodError java.lang.ClassNotFoundException java.lang.IllegalAccessError java.lang.IllegalAccessException java.lang.InstantiationError java.lang.InstantiationException java.lang.InvocationTargetException java.lang.NoClassDefFoundError java.lang.NoSuchFieldError java.lang.NoSuchFieldException java.lang.NoSuchMethodError java.lang.NoSuchMethodException
-
No error is reported, but one of the following issues occur:
-
Logs are not generated or the Log4j configuration does not take effect. In most cases, this issue occurs because the dependency contains the Log4j configuration. To resolve this issue, you must check whether the dependency in the JAR file of your deployment contains the Log4j configuration. If the dependency contains the Log4j configuration, you can configure exclusions in the dependency to remove the Log4j configuration.
noteIf you use different versions of Log4j, you must use maven-shade-plugin to relocate Log4j-related classes.
-
The remote procedure call (RPC) fails. By default, errors caused by dependency conflicts during Akka RPCs of Flink are not recorded in logs. To check these errors, you must enable debug logging. For example, a debug log records Cannot allocate the requested resources. Trying to allocate
ResourceProfile{xxx}. However, the JobManager log stops at the message Registering TaskManager with ResourceID xxx and does not display any information until a resource request times out and displays the message NoResourceAvailableException. In addition, TaskManagers continuously report the error message Cannot allocate the requested resources. Trying to allocateResourceProfile{xxx}. Cause: After you enable debug logging, the RPC error message InvocationTargetException appears. In this case, slots fail to be allocated for TaskManagers and the status of the TaskManagers becomes inconsistent. As a result, slots cannot be allocated and the error cannot be fixed.
-
Cause
- The JAR package of your deployment contains unnecessary dependencies, such as the dependencies for basic configurations, Flink, Hadoop, and Log4j. As a result, dependency conflicts occur and cause some issues.
- The dependency that corresponds to the connector that is required for your deployment is not included in the JAR package.
Troubleshooting
- Check whether the pom.xml file of your deployment contains unnecessary dependencies.
- Run the jar tf foo.jar command to view the content of the JAR package and determine whether the package contains the content that causes dependency conflicts.
- Run the mvn dependency:tree command to check the dependency relationship of your deployment and determine whether dependency conflicts exist.
Solution
Ververica recommends that you set scope to provided for the dependencies for basic configurations. This way, the dependencies for basic configurations are not included in the JAR package of your deployment.
- DataStream Java
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
- DataStream Scala
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-scala_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
- DataSet Java
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
- DataSet Scala
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-scala_2.11</artifactId>
<version>${flink.version}</version>
<scope>provided</scope>
</dependency>
Add the dependencies that correspond to the connectors required for the deployment, and set scope to compile. This way, the dependencies that correspond to the required connectors are included in the JAR package. The default value of scope is compile. In the following code, the Kafka connector is used as an example.
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-connector-kafka_2.11</artifactId>
<version>${flink.version}</version>
</dependency>
Ververica recommends that you do not add the dependencies for Flink, Hadoop, or Log4j. Take note of the following exceptions: If the deployment has direct dependencies for basic configurations or connectors, Ververica recommends that you set scope to provided. Sample code:
<dependency>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
<scope>provided</scope>
</dependency>
If the deployment has indirect dependencies for basic configurations or connectors, Ververica recommends that you configure exclusions to remove the dependencies. Sample code:
<dependency>
<groupId>foo</groupId>
<artifactId>bar</artifactId>
<exclusions>
<exclusion>
<groupId>org.apache.hadoop</groupId>
<artifactId>hadoop-common</artifactId>
</exclusion>
</exclusions>
</dependency>
Note on communication with external file systems
In Flink, the FileSystem module manages the communication with all external file systems (e.g. Hadoop HDFS, AWS S3, Azure blob storage, etc.). One file path schema can only use one single auth method. However, as a fully-managed cloud service, Ververica Cloud needs to connect with external storage for two layers:
- System layer (Ververica Cloud-managed)
- User layer (Users’ sources and sinks)
Ververica Cloud uses two file path schemas to differentiate the auth for the above two layers. In order to maintain consistent behavior among users, we introduced the s3i:// schema dedicated to the system layer.
-
All managed S3 paths use the
s3i://schema. This appears in the Ververica Cloud Console UI or logs (for example, paths for checkpoints, savepoints, and all artifacts references) but the path is not editable directly. -
Users can use the
s3://schema when their jobs communicate with external S3 services via their own S3 connector (e.g. sources and sinks).