Manage Kafka Schema Registry catalog
Use the Kafka Schema Registry Catalog to integrate Flink SQL with Confluent Schema Registry or AWS Glue Schema Registry. This allows you to manage schemas and use Kafka topics with associated schemas directly as Flink tables.
Background
A schema registry is a centralized repository for managing and validating data schemas used in streaming platforms like Apache Kafka. It ensures data consistency between producers and consumers and enables safe schema evolution. Flink supports integration with both Confluent Schema Registry and AWS Glue Schema Registry through this catalog, primarily for the Avro format.
Prerequisites
- Access to a running Kafka cluster.
- A deployed and accessible schema registry (Confluent or AWS Glue).
- Network connectivity between your Flink environment and the schema registry.
- Appropriate credentials and permissions for the schema registry.
Supported Schema Registries
| Registry | Formats Supported | Deployment | Integration Method |
|---|---|---|---|
| Confluent Schema Registry | Avro | Self-managed or Confluent Cloud | REST API, Flink Catalog |
| AWS Glue Schema Registry | Avro | AWS-managed | AWS SDK, Flink Catalog |
Catalog Features
The Kafka Schema Registry Catalog enables you to discover, manage, and use schemas registered in Confluent or AWS Glue as Flink tables. This simplifies schema management and enforces compatibility across streaming applications. The underlying logic for both registry types is shared within the catalog, differing mainly in connection details and specific WITH options.
Flink Catalog & Schema Registry Concepts Mapping
The catalog maps Flink concepts to Schema Registry and Kafka concepts as follows:
| Flink Concept | Confluent SR Equivalent | AWS Glue SR Equivalent | Kafka Equivalent |
|---|---|---|---|
| Catalog Name | (User-defined in Flink) | (User-defined in Flink) | N/A |
| Database Name | kafka (Fixed) | kafka (Fixed) | N/A |
| Registry Name | N/A | (User-defined in AWS) | N/A |
| Table Name | Two Subjects: <table_name>-key & <table_name>-value | Two Schema IDs: <table_name>-key & <table_name>-value | One Topic: <table_name> |
- In Confluent Schema Registry, schemas are grouped by subject. Flink table names map directly to these subject names (excluding the
-key/-valuesuffix). - In AWS Glue Schema Registry, schemas are identified by IDs within a named registry. You must create the registry in AWS Glue before creating the Flink catalog.
Creating a Catalog
You must first create a catalog linked to your specific schema registry.
Confluent Schema Registry
This statement creates a catalog named confluent_sr_catalog connected to a Confluent Schema Registry.
type = 'kafka': Specifies the catalog type.properties.bootstrap.servers: Your Kafka broker address(es).url: The endpoint of your Confluent Schema Registry service.format = 'avro-confluent': Indicates the use of Confluent's Avro format.key.fields-prefix/value.fields-prefix: Prefixes applied to key/value fields in the Flink table schema to avoid name collisions.
CREATE CATALOG confluent_sr_catalog WITH (
'type' = 'kafka',
'properties.bootstrap.servers' = 'kafka.example.com:9092',
'url' = '[http://confluent-sr.example.com:8081](http://confluent-sr.example.com:8081)',
'format' = 'avro-confluent',
'key.fields-prefix' = 'k_',
'value.fields-prefix' = 'v_'
);
AWS Glue Schema Registry
This statement creates a catalog named glue_sr_catalog connected to an AWS Glue Schema Registry.
type = 'kafka': Specifies the catalog type.properties.bootstrap.servers: Your Kafka broker address(es).format = 'avro-glue': Indicates the use of AWS Glue's Avro format.aws.glue.region: The AWS region where your registry resides.aws.glue.registry.name: The name you gave your schema registry in AWS Glue.aws.glue.aws.credentials.provider.basic.accesskeyid/secretkey: Explicit AWS credentials (alternatively, use IAM roles or environment variables).key.fields-prefix/value.fields-prefix: Prefixes applied to key/value fields.
CREATE CATALOG glue_sr_catalog WITH (
'type' = 'kafka',
'properties.bootstrap.servers' = 'kafka.example.com:9092',
'format' = 'avro-glue',
'aws.glue.region' = 'us-east-1',
'aws.glue.registry.name' = 'my-registry',
'aws.glue.aws.credentials.provider.basic.accesskeyid' = '<your-access-key>',
'aws.glue.aws.credentials.provider.basic.secretkey' = '<your-secret-key>',
'key.fields-prefix' = 'k_',
'value.fields-prefix' = 'v_'
);
After creating the catalog, activate it for your current session:
USE CATALOG confluent_sr_catalog; -- or glue_sr_catalog
You can now manage tables within this catalog.
Catalog Options
The following table summarizes the primary options used when creating a Kafka Schema Registry Catalog.
| Option | Required | Description |
|---|---|---|
type | Yes | Must be 'kafka'. |
properties.bootstrap.servers | Yes | The address of the Kafka Broker. Essential for establishing a connection to the Kafka cluster. |
format | Yes | Specifies the serialization format and target Schema Registry. Use 'avro-confluent' for Confluent SR or 'avro-glue' for AWS Glue SR. |
url | Required for 'avro-confluent' | The endpoint URL of the Confluent Schema Registry (e.g., http://localhost:8081). It is essential to provide this URL when using the avro-confluent format to ensure proper schema management. |
key.fields-prefix | Required for 'avro-confluent' (cannot be empty if used) | Prefix applied to key fields in the Flink table schema. |
value.fields-prefix | Required for 'avro-confluent' (cannot be empty if used) | Prefix applied to value fields in the Flink table schema. |
aws.glue.region | Required for 'avro-glue' | AWS region of the AWS Glue Schema Registry. |
aws.glue.registry.name | Required for 'avro-glue' | Name of the registry in AWS Glue Schema Registry. |
aws.glue.aws.credentials.provider.basic.accesskeyid | Required for 'avro-glue' | AWS access key ID. Overrides environment variables or instance profiles. |
aws.glue.aws.credentials.provider.basic.secretkey | Required for 'avro-glue' | AWS secret key. Overrides environment variables or instance profiles. |
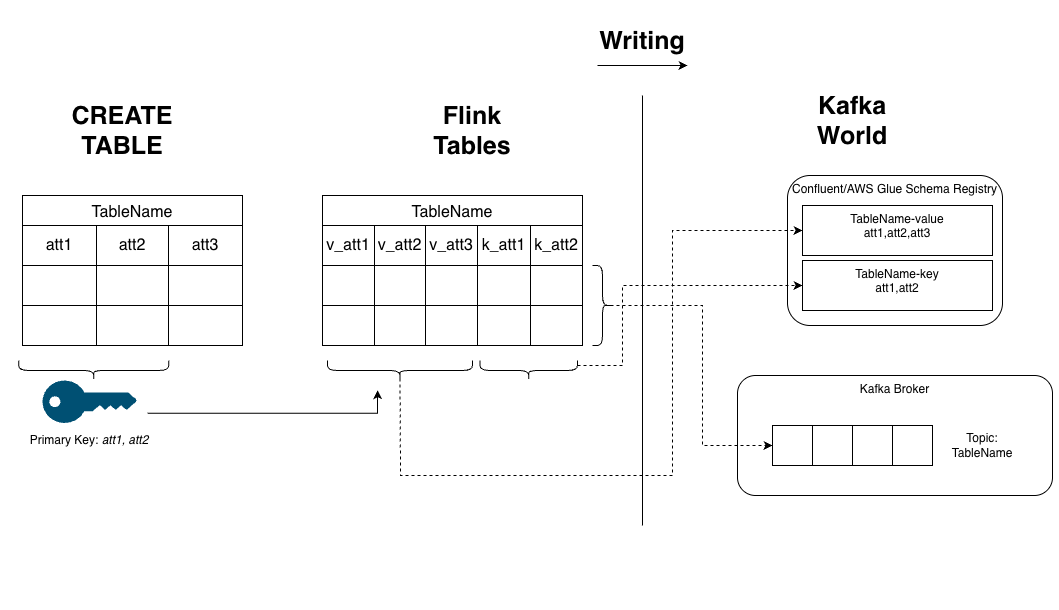
Creating a Table
When you execute a CREATE TABLE statement within the catalog, Flink automatically registers two schemas in the Schema Registry under corresponding subjects/IDs: one for the key (<table_name>-key) and one for the value (<table_name>-value). The Kafka topic name will match the Flink table name.
Fields designated as PRIMARY KEY in Flink SQL are included in both the key and value schemas. In the resulting Flink table schema, these key fields are duplicated, once with the key.fields-prefix and once with the value.fields-prefix.
CREATE TABLE TableName (
att1 STRING,
att2 INT,
att3 DOUBLE,
PRIMARY KEY (att1, att2) NOT ENFORCED
);
After creation, the Flink table TableName will have columns like v_att1, v_att2, v_att3, k_att1, k_att2.
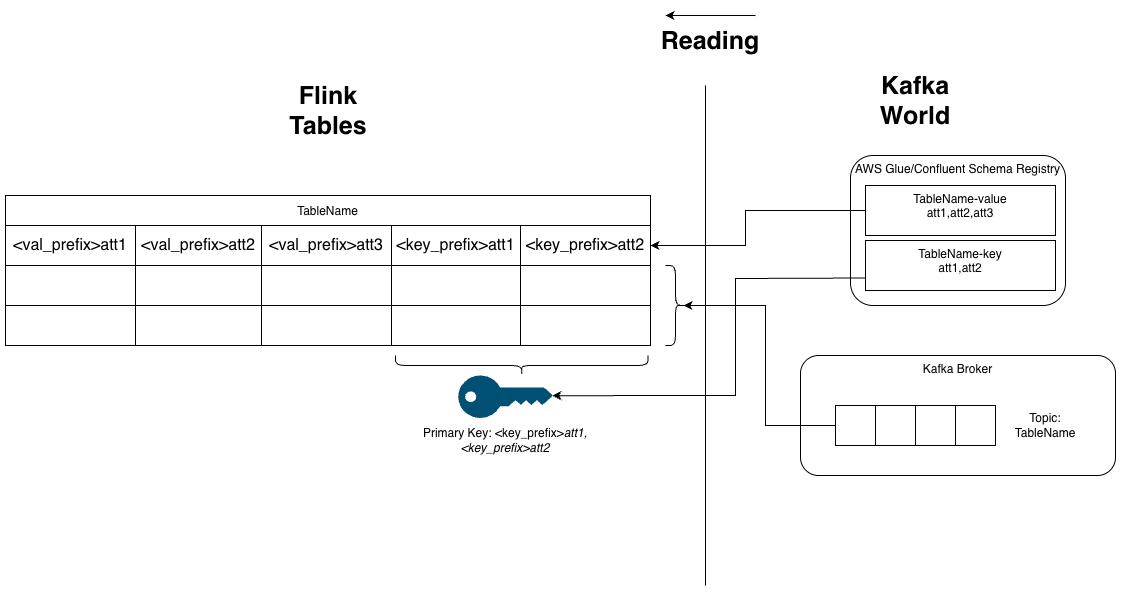
Querying and Writing Data
All subsequent SELECT, INSERT, and ALTER statements must operate on the table schema that includes the key/value prefixes.
When writing data using INSERT INTO ... SELECT ... FROM, you must specify the explicit column names in your SELECT projection. Using SELECT * is not supported because the source table schema includes Kafka metadata fields (partition, offset, timestamp) that cannot be written to the sink.
The typical column order in the Flink table schema places value-prefixed fields before key-prefixed fields. Ensure your SELECT projection matches the target table's column order if you don't explicitly list columns in the INSERT INTO clause.
USE CATALOG confluent_sr_catalog; -- or glue_sr_catalog
-- Create a second table with the same schema
CREATE TABLE TableName2 (
att1 STRING,
att2 INT,
att3 DOUBLE,
PRIMARY KEY (att1, att2) NOT ENFORCED
);
-- Insert sample data into the first table (using explicit columns)
INSERT INTO TableName (k_att1, k_att2, v_att1, v_att2, v_att3) VALUES ('key1', 1, 'key1', 1, 10.5);
-- Copy data from TableName to TableName2
INSERT INTO TableName2
SELECT v_att1, v_att2, v_att3, k_att1, k_att2 -- Explicit projection required
FROM TableName
/*+ OPTIONS (
'scan.startup.mode' = 'earliest-offset'
) */;
Using Hints for Connector Options
Specific Kafka connector options (like scan.startup.mode, scan.bounded.mode) cannot be set at the catalog level, as they would apply too broadly. Instead, use SQL hints /*+ OPTIONS (...) */ within your query to override these options for that specific query only.
-- Run a bounded query that stops at the latest offset
INSERT INTO TableName2
SELECT v_att1, v_att2, v_att3, k_att1, k_att2
FROM TableName
/*+ OPTIONS (
'scan.startup.mode' = 'earliest-offset',
'scan.bounded.mode' = 'latest-offset'
) */;
An INSERT INTO ... SELECT ... FROM query creates an unbounded streaming job by default. Use the 'scan.bounded.mode' = 'latest-offset' hint to run it as a finite batch job for testing.
Modifying a Table Schema
The catalog supports limited ALTER TABLE operations:
- You can
ADDorDROPcolumns using their prefixed names (e.g.,v_new_column). - You cannot modify or drop columns that are part of the
PRIMARY KEY(neither thek_nor thev_prefixed versions).
-- Add a new value column
ALTER TABLE TableName ADD (v_new_col STRING);
-- Drop an existing value column (must not be part of the PK)
ALTER TABLE TableName DROP (v_att3);
Limitations
| Limitation | Notes |
|---|---|
| Schema Evolution | Currently, only the BACKWARD compatibility policy is fully supported for schema changes made via ALTER TABLE. |
ALTER TABLE Operations | Only ADD and DROP column operations are supported. Columns that are part of the PRIMARY KEY (both k_ and v_ prefixed versions) cannot be modified or dropped. |
Explicit Columns in SELECT | You must explicitly list columns in INSERT INTO ... SELECT ... statements. SELECT * is not supported because the source schema includes Kafka metadata (partition, offset, timestamp) that cannot be written. |
| Topic Partitioning | The catalog does not manage Kafka topic partitioning or replication settings. |
| Case Sensitivity | Flink table names must exactly match the corresponding Kafka topic names and Schema Registry subject/schema names, respecting case sensitivity. |
Ververica Deployment Workflow Example
This workflow demonstrates using the Confluent Schema Registry Catalog with a Ververica deployment. The steps are similar for the AWS Glue Schema Registry Catalog, differing mainly in the CREATE CATALOG options.
1. Create the Catalog
In the SQL Editor, execute the CREATE CATALOG statement for Confluent SR (as shown previously), providing your Kafka and Schema Registry endpoints. To execute the statement:
- Highlight the entire
CREATE CATALOGcode. - Right-click the highlighted text.
- Select Run from the context menu.
After execution, the confluent_sr_catalog will appear in the Catalogs panel on the left, containing a single database named kafka.
2. Create Tables
Ensure confluent_sr_catalog is selected or use USE CATALOG confluent_sr_catalog;. Execute CREATE TABLE statements for the tables you need (e.g., TableName and TableName2 from the examples above) using the same Run method. The new tables will appear under the kafka database in the Catalogs panel.
3. Insert Initial Data
To populate TableName with sample data, execute an INSERT INTO ... VALUES statement. Remember to specify the prefixed column names (k_att1, k_att2, v_att1, etc.). Deploy this SQL as a job from the editor. Since it's a bounded insert, the job will run and finish. You can start the deployment manually from the Deployments panel.
4. Migrate Data Between Tables
Execute the INSERT INTO TableName2 SELECT ... FROM TableName query (using explicit columns and optionally the scan.bounded.mode hint). Deploy this SQL. If using the bounded mode hint, the job will run, copy the data, and finish.
5. Alter a Table Schema
Execute an ALTER TABLE TableName DROP (v_att3); statement to remove a non-key column. After execution, you can inspect the updated schema by clicking the table name in the Catalogs panel. Subsequent reads from the table will reflect this change, respecting the schema evolution policy.