MySQL & MySQL CDC
This topic explains how to use the MySQL connector.
Background
MySQL connector support all databases that are compatible with the MySQL protocol. The databases include Amazon RDS MySQL and self-managed MySQL databases.
The information supported by the MySQL connector is as follows.
| Category | Details |
|---|---|
| table type | Source table, dimension table and result table |
| job mode | streaming |
| formats | Not applicable |
| metrics | Dimension table and result table: none. Source table: 1. currentFetchEventTimeLag: the interval between data generation and pulling to the Source Operator. This metric is only valid in the binlog phase, and the value is always 0 in the Snapshot phase. 2. currentEmitEventTimeLag: the interval between data generation and sent from the Source Operator. This metric is only valid in the binlog phase, and the value is always 0 in the Snapshot phase. 3. sourceIdleTime: how long the source table has not generated new data so far. |
| API | Datastream and SQL |
| Support to delete or update the data of a result table | Yes |
Prerequisites
Source table
A network connection is established between your MySQL database and Ververica Cloud.
-
The MySQL server meets the following requirements:
- The MySQL version is 5.6, 5.7 or 8.0.X.
- Binary log is enabled. (Head to the Enabling Binary Log section)
- The binlog_row_image parameter is set to FULL. (Setting binlog_row_image)
-
The interactive_timeout and wait_timeout parameters are configured in the MySQL configuration file. (Configuring interactive_timeout and wait_timeout)
-
A MySQL user is created and granted the SELECT, SHOW DATABASES, REPLICATION SLAVE, and REPLICATION CLIENT permissions. For example:
CREATE USER 'user'@'%' IDENTIFIED BY 'pwd';GRANT SELECT, SHOW DATABASES, REPLICATION SLAVE, REPLICATION CLIENT ON *.* TO 'user'@'%' WITH GRANT OPTION;FLUSH PRIVILEGES;
Dimension table and result table
- A MySQL database and a MySQL table are created.
- An IP address whitelist is configured.
Limits
Transport Layer Security (TLS)
The RDS in AWS does not support TLS. However, MySQL connector support TLS by default (because MySQL enables it by default). To solve the mis-match please follow the instructions below.
-
Reading data from a MySQL table
When you want to read data from a MySQL table in the default catalog, it's necessary to disable SSL for the JDBC connection. To do this, add the following property to your
jdbc.properties.jdbc.properties.useSSL=falseCREATE TABLE `system`.`default`.`MysqlTable2` (
`id` INT NOT NULL,
`name` VARCHAR(255) NOT NULL,
`address` VARCHAR(1024),
`phone_number` VARCHAR(512),
`email` VARCHAR(255),
CONSTRAINT `PK_3386` PRIMARY KEY (`id`) NOT ENFORCED
) WITH (
'jdbc.properties.useSSL' = 'false',
'hostname' = 'vvc-us-west-prod-db.cluster-clrjoknilssk.us-west-1.rds.amazonaws.com',
'password' = 'vvc-demo',
'connector' = 'mysql',
'port' = '3306',
'database-name' = 'vvc',
'table-name' = 'user_1',
'username' = 'admin'
);This setting ensures that the connection between your application and the MySQL database does not use SSL encryption.
-
Writing data to a MySQL table
When writing data to a MySQL table in the default catalog, it's necessary to disable TLS. To do this, you can override the connection URL by adding the useSSL=false parameter. However, you still need to provide the hostname and database name for validation purposes. The connection URL can also be used to specify any other JDBC connection options supported by the JDBC driver.
Here's an example of how to construct a connection URL with TLS disabled and the required hostname and database name:
jdbc:mysql://your_hostname:3306/your_database_name?useSSL=falseReplace
your_hostnamewith the actual hostname of your MySQL server andyour_database_namewith the name of the database you want to connect to.CREATE TABLE SinkMysqlTable (
id INTEGER NOT NULL PRIMARY KEY,
name VARCHAR(255) NOT NULL,
address VARCHAR(1024),
phone_number VARCHAR(512),
email VARCHAR(255)
) WITH (
'connector' = 'mysql',
'hostname' = 'vvc-us-west-prod-db.cluster-clrjoknilssk.us-west-1.rds.amazonaws.com',
'port' = '3306',
'database-name' = 'vvc',
'table-name' = 'user_2',
'username' = 'admin',
'password' = 'vvc-demo',
'url' = 'jdbc:mysql://vvc-us-west-prod-db.cluster-clrjoknilssk.us-west-1.rds.amazonaws.com:3306/vvc?useSSL=false'
);
Change Data Capture (CDC) source table
MySQL CDC source tables do not support watermarks. If you need to perform window aggregation on a MySQL CDC source table, you can convert time fields into window values and use GROUP BY to aggregate the window values. For example, if you want to calculate the number of orders and sales per minute in a store, you can use the following code:
SELECT shop_id, DATE_FORMAT(order_ts, 'yyyy-MM-dd HH:mm'), COUNT(*), SUM(price)
FROM order_mysql_cdc
GROUP BY shop_id, DATE_FORMAT(order_ts, 'yyyy-MM-dd HH:mm')
Only MySQL users who are granted specific permissions can read full data and incremental data from a MySQL CDC source table. The permissions include SELECT, SHOW DATABASES, REPLICATION SLAVE, and REPLICATION CLIENT.
Quick start
- MySQL tables could be used as a source table as follows:
CREATE TEMPORARY TABLE mysqlcdc_source (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
CREATE TEMPORARY TABLE blackhole_sink(
order_id INT,
customer_name STRING
) WITH (
'connector' = 'blackhole'
);
INSERT INTO blackhole_sink
SELECT order_id, customer_name FROM mysqlcdc_source;
- MySQL source tables will use MySQL CDC source. Please confirm that the prerequisites have been met.
- Each MySQL CDC source table needs to be explicitly configured with a different Server ID. See more details in Precautions.
- MySQL tables could be used as a dimension table in the lookup join as follows:
CREATE TEMPORARY TABLE datagen_source(
a INT,
b BIGINT,
c STRING,
`proctime` AS PROCTIME()
) WITH (
'connector' = 'datagen'
);
CREATE TEMPORARY TABLE mysql_dim (
a INT,
b VARCHAR,
c VARCHAR
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
CREATE TEMPORARY TABLE blackhole_sink(
a INT,
b STRING
) WITH (
'connector' = 'blackhole'
);
INSERT INTO blackhole_sink
SELECT T.a, H.b
FROM datagen_source AS T JOIN mysql_dim FOR SYSTEM_TIME AS OF T.`proctime` AS H ON T.a = H.a;
- MySQL tables could be used as a result table as follows:
CREATE TEMPORARY TABLE datagen_source (
`name` VARCHAR,
`age` INT
) WITH (
'connector' = 'datagen'
);
CREATE TEMPORARY TABLE mysql_sink (
`name` VARCHAR,
`age` INT
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
INSERT INTO mysql_sink
SELECT * FROM datagen_source;
Precautions
CDC source table
Each MySQL CDC source table needs to be explicitly configured with a different Server ID.
-
Why does MySQL CDC need Server ID?
- Each client that synchronizes database data will have a unique ID, namely Server ID. MySQL server will maintain the network connection and Binlog offset according to the ID. If a large number of clients with different Server IDs connect to MySQL Server together, the CPU of MySQL Server may increase sharply, affecting the stability of online business. If multiple MySQL CDC source tables share the same Server ID, and the source tables cannot be merged, the Binlog offset will be confused, and more or less data will be read. Errors of Server ID conflicts may also occur, so it is recommended that each MySQL CDC source table be configured with a different Server ID.
-
How to config Server ID?
- Server ID can be specified in DDL or configured through dynamic hints. It is recommended to configure the Server ID through dynamic hints.
-
Configuration of Server IDs in Different Scenarios
-
When the incremental snapshot framework is not enabled or the table’s parallelism is 1, a specific Server ID can be specified.
SELECT * FROM source_table /*+ OPTIONS('server-id'='123456') */ ; -
When the incremental snapshot framework is enabled and the table’s parallelism is greater than 1, you need to specify the range of Server IDs. Please ensure that the number of available Server IDs within the range is not less than the parallelism. Assuming that the parallelism is 3, it can be configured as follows:
SELECT * FROM source_table /*+ OPTIONS('server-id'='123456-123458') */ ; -
When combined with CTAS for data synchronization, if the configuration of the CDC source tables is the same, the source tables will be automatically merged. At this time, the same Server ID can be configured for multiple CDC source tables.
BEGIN STATEMENT SET;
CREATE TABLE IF NOT EXISTS `database1`.`user`
AS TABLE `mysql`.`tpcds`.`user`
/*+ OPTIONS('server-id'='8001-8004') */;
CREATE TABLE IF NOT EXISTS `database2`.`user`
AS TABLE `mysql`.`tpcds`.`user`
/*+ OPTIONS('server-id'='8001-8004') */;
END; -
When the job contains multiple MySQL CDC source tables, and the CTAS statement is not used to synchronize, the source tables cannot be merged, and a different Server ID needs to be provided for each CDC source table.
select * from
source_table1 /*+ OPTIONS('server-id'='123456-123457') */
left join
source_table2 /*+ OPTIONS('server-id'='123458-123459') */
on source_table1.id=source_table2.id;
-
Result table
- You must declare at least one non-primary key in the DDL statement. Otherwise, an error is returned.
- The parameter
scan.incremental.snapshot.chunk.key-columnis required when using the MySQL connector as a source on a table that doesn’t have a primary key. - NOT ENFORCED indicates that Flink does not perform mandatory verification on the primary key. You must ensure the correctness and integrity of the primary key.
DDL syntax
CREATE TABLE mysqlcdc_source (
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = '<yourHostname>',
'port' = '3306',
'username' = '<yourUsername>',
'password' = '<yourPassword>',
'database-name' = '<yourDatabaseName>',
'table-name' = '<yourTableName>'
);
Enable binlog format
To use MySQL catalog, it's necessary to enable binlog in RDS. The underlying connector for this process is mysql-cdc. You will need to create a new parameter group based on the existing AWS one, change the binlog_format from OFF to ROW, and use this new parameter group to set up RDS or reconfigure RDS after its creation.
Applying parameter group changes only works if the MySQL database is based on the Aurora engine. This applies both when creating and modifying a database. The instructions in this section will not work for a regular MySQL engine.
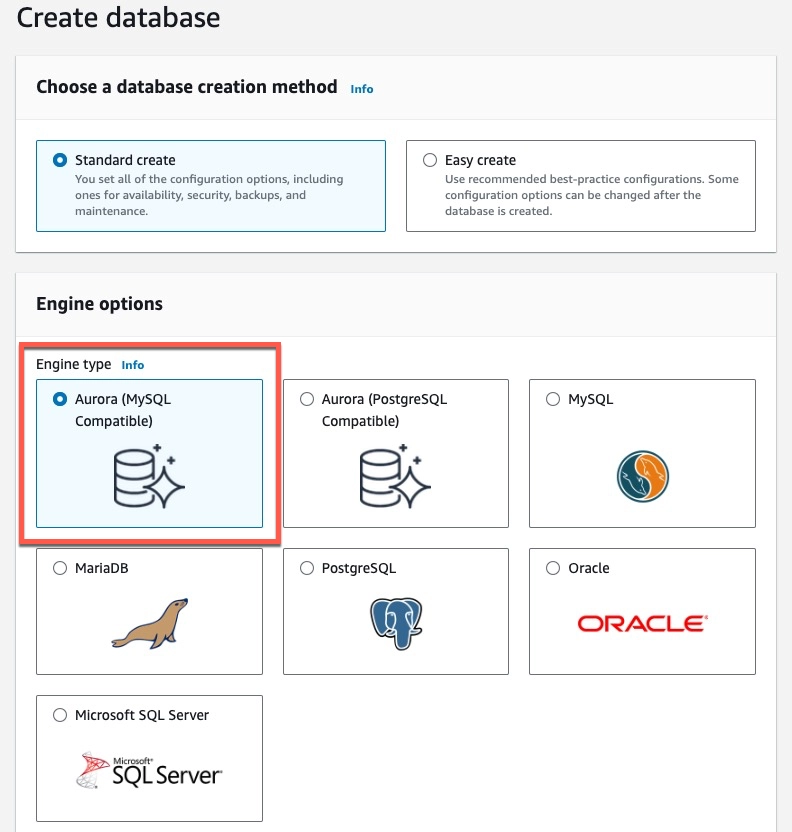
The steps are as follows:
-
Display your Amazon AWS RDS console.
-
To create a new group, click on Parameters group on the left sidebar menu and then click Create parameter group.
-
In the Parameter group family field, select the parameter you want to apply.
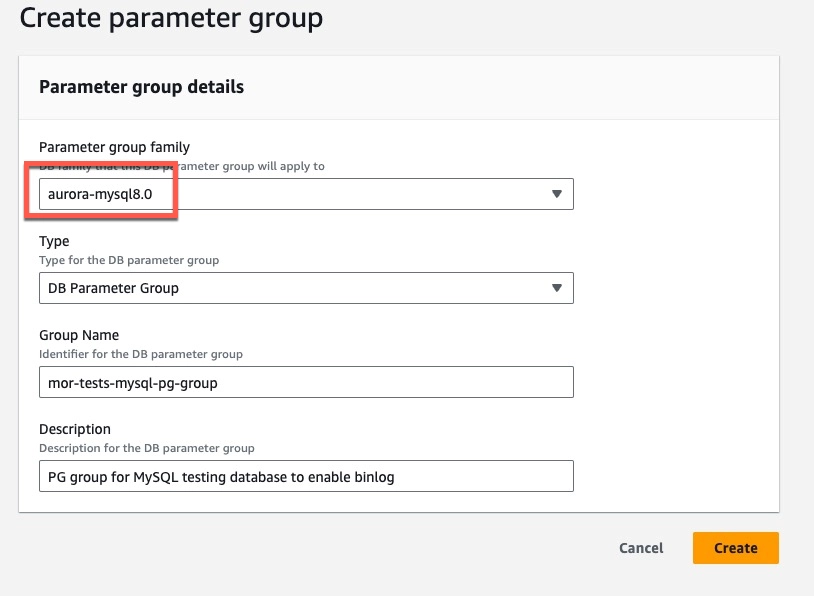 note
noteSelect a specific group family that starts with the
aurora-prefix, otherwise, you will not be able to select anything for the Type field. It is only available for aurora- families of database. -
In the Type field, select DB Cluster Parameter Group.
-
Name your group and fill in the description field - they are both mandatory.
-
Click Create.
-
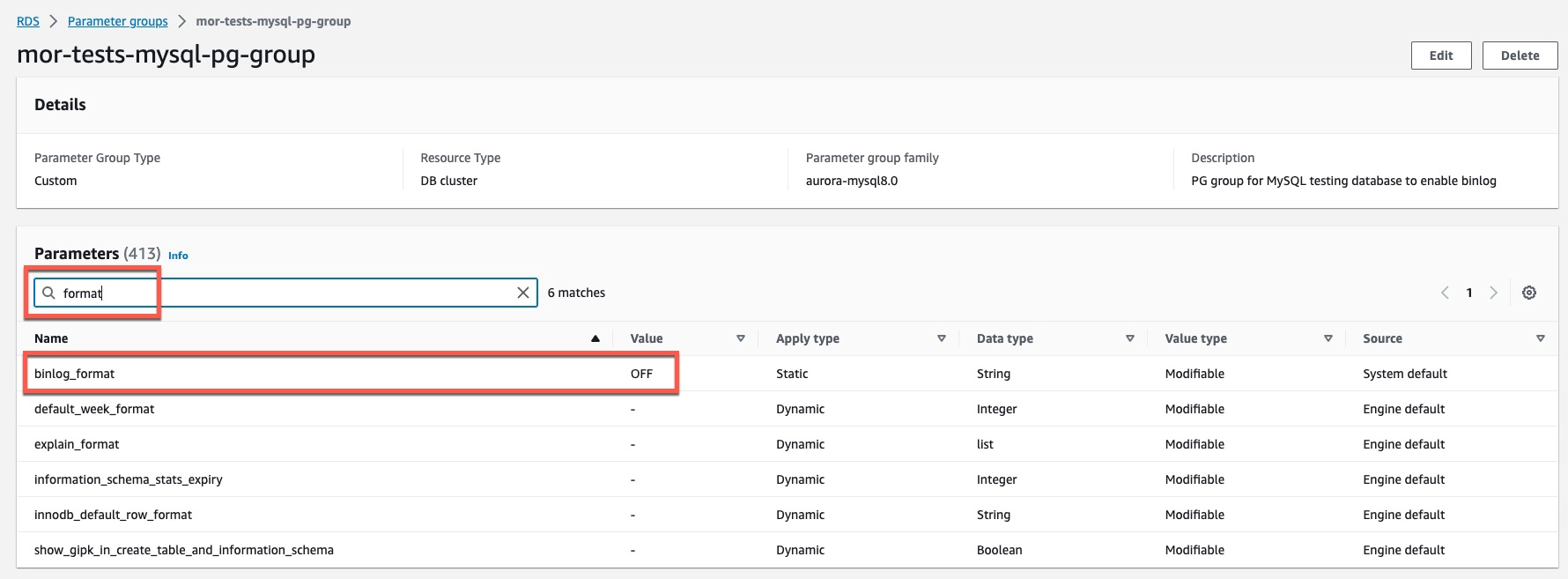
Click on the name of your parameter group.
-
Click Edit and type
formatin the search field of the Parameters section. -
Change the value of
binlog_formattoROWand click Save changes
If you want to create a database with a newly created parameter group:
- Click Create database.
- Scroll down to the Additional configuration section and extend the collapsible menu.
- In the DB cluster parameter group field, select your new group
If you want to modify a database with a newly created parameter group:
- Click Databases in the left sidebar menu.
- Click on your database >> Modify
- In the Additional configuration section, change the field value to your parameter group in the DB cluster parameter group field.
- Click Continue >> Modify cluster
- For the changes to take effect, you need to reboot all databases from the Actions menu.
Parameters in the WITH clause
Common parameters
| Parameter | Description | Required | Type | Default | Note |
|---|---|---|---|---|---|
| connector | The type of the source table. | Y | STRING | N/A. | You can set this parameter to mysql-cdc or mysql for source tables. Set the value to mysql for dimension tables and result tables. |
| hostname | The IP address or hostname that is used to access the MySQL database. | Y | STRING | N/A. | N/A. |
| username | The username that is used to access the MySQL database. | Y | STRING | N/A. | N/A. |
| password | The password that is used to access the MySQL database. | Y | STRING | N/A. | N/A. |
| database-name | The name of the MySQL database. | Y | STRING | N/A. | If you want to read data from multiple databases, you can set this parameter to a regular expression. |
| table-name | The name of the MySQL table. | Y | STRING | N/A. | If you want to read data from multiple tables, you can set this parameter to a regular expression. |
| port | The port number that is used to access the MySQL database. | N | INTEGER | 3306 | N/A. |
Unique to source table
| Parameter | Description | Required | Type | Default | Note |
|---|---|---|---|---|---|
| server-id | The ID that is allocated to a database client. | N | STRING | A value in the range of 5400 to 6400 is randomly generated. | The ID must be unique in a MySQL cluster. Ververica recommends that you configure a unique server ID for each deployment in the same database. This parameter can also be set to an ID range, such as 5400-5408. If the incremental snapshot algorithm is enabled, parallel reading is supported. In this case, Ververica recommends that you set this parameter to an ID range so that each parallel deployment uses a unique ID. |
| scan.incremental.snapshot.enabled | Specifies whether to enable the incremental snapshot algorithm. | N | BOOLEAN | true | The incremental snapshot algorithm is a new mechanism that is used to read snapshots of full data. Compared with the original snapshot reading algorithm, the incremental snapshot algorithm has the following advantages: 1. When the MySQL CDC connector reads full data, the MySQL CDC connector can read data from multiple MySQL databases at the same time. 2. When the MySQL CDC connector reads full data, the MySQL CDC connector can generate checkpoints for chunks. 3. When the MySQL CDC connector reads full data, the MySQL CDC connector does not need to execute the FLUSH TABLES WITH READ LOCK statement to obtain a global read lock. 4. If you want the MySQL CDC connector to support parallel reading, a unique server ID must be allocated to each parallel reader. Therefore, you must set server-id to a range that is greater than or equal to the value of the Parallelism parameter. For example, you can set server-id to 5400-6400. |
| scan.incremental.snapshot.chunk.size | The chunk size of the table. The chunk size indicates the number of rows. | N | INTEGER | 8096 | If the incremental snapshot algorithm is enabled, the table is split into multiple chunks for data reading. Before data in a chunk is read, the data is cached in the memory. Therefore, if the chunk size is too large, an out of memory (OOM) error may occur. If the chunk size is small, a small number of data records are read after fault recovery. This reduces data throughput. |
| scan.snapshot.fetch.size | The maximum number of records that can be extracted each time full data of a table is read. | N | INTEGER | 1024 | N/A. |
| scan.startup.mode | The startup mode when data is consumed. | N | STRING | initial | Valid values: initial: When the MySQL CDC connector starts for the first time, Ververica Cloud scans all historical data and reads the most recent binary log data. This is the default value. latest-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the most recent offset, instead of scanning all historical data. This way, Ververica Cloud reads only the most recent incremental data after the connector starts. earliest-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the earliest offset, instead of scanning all historical data. specific-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the specific offset, instead of scanning all historical data. Specify to start from a specific Binlog file name and offset by scan.startup.specific-offset.file and scan.startup.specific-offset.pos . Specify to start from a specific GTID set by scan.startup.specific-offset.gtid-set . timestamp: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the specific timestamp, instead of scanning all historical data. The timestamp is specified by scan.startup.timestamp-millis in milliseconds. |
| scan.startup.specific-offset.file | N | STRING | N/A. | When using this configuration, scan.startup.mode must be set to specific-offset. The format of the file name is, for example, mysql-bin.000003. | |
| scan.startup.specific-offset.pos | N | INTEGER | N/A. | When using this configuration, scan.startup.mode must be set to specific-offset. | |
| scan.startup.specific-offset.gtid-set | N | STRING | N/A. | When using this configuration, scan.startup.mode must be set to specific-offset. The format of the GTID set is, for example, 24DA167-0C0C-11E8-8442-00059A3C7B00:1-19. | |
| scan.startup.timestamp-millis | N | LONG | N/A. | When using this configuration, scan.startup.mode must be set to timestamp. The timestamp unit is milliseconds. Important! When using the specified timestamp, MySQL CDC source table will read from the earliest binlog until the timestamp of the binlog event is greater than or equal to the specified timestamp and then start sending data downstream. Please ensure that the binlog file corresponding to the specified timestamp has not been cleaned up on the database and can be read. | |
| server-time-zone | Required only in 6.0.2 or earlier | STRING | If you do not configure this parameter, the system uses the time zone of the environment in which the Ververica Cloud deployment runs as the time zone of the database server. The time zone is the time zone of the zone that you selected. | Example: Asia/Shanghai. This parameter determines how to convert data in the MySQL database from the TIMESTAMP type to the STRING type. | |
| debezium.min.row.count.to.stream.results | N | INTEGER | 1000 | Ververica Cloud reads data from a MySQL source table in one of the following modes: Full data read: reads all data from the table and writes the data to the memory. Data is read at a high speed, but memory space is consumed. If the source table contains a large amount of data, an OOM error may occur in this mode. Batch data read: reads data of a specific number of rows at a specified point in time until all data is read. OOM is prevented even if the table contains a large amount of data. However, data is read at a low speed. | |
| connect.timeout | The maximum duration for which the connector waits before the connector makes a retry if the connection to the MySQL database server times out. | N | DURATION | 30 seconds | N/A. |
| connect.max-retries | The maximum number of retries after the connection to the MySQL database server fails. | N | INTEGER | 3 | N/A. |
| connection.pool.size | The size of the database connection pool. | N | INTEGER | 20 | The database connection pool is used to reuse connections. This can reduce the number of database connections. |
| jdbc.properties. | Custom Java Database Connectivity (JDBC) URL parameters. | N | STRING | N/A. | You can pass the custom JDBC parameters. For example, if you do not want to use the SSL protocol, you can set the jdbc.properties.useSSL parameter to false. For more information about the JDBC parameters, see Mysql Configuration Properties . |
| heartbeat.interval | The interval at which the source moves forward the binary log file position by using heartbeat events. | N | DURATION | 30 seconds | Heartbeat events are used to identify the latest position of the binary log file that is read from the source. For slowly updated tables in MySQL, the binary log file position cannot automatically move forward. The source can move forward the binary log file position by using heartbeat events. This can prevent the binary log file position from expiring. If the binary log file position expires, the deployment fails to run and cannot recover from the failure. If this occurs, you can only select Start without state for Start Method and specify Start Time for Reading Data to start the deployment. |
Unique to dimension table
| Parameter | Description | Required | Type | Default | Note |
|---|---|---|---|---|---|
| lookup.cache.strategy | The cache policy. | N | STRING | None | Valid values: None: indicates that data is not cached. This is the default value. LRU: indicates that only the specified data in the dimension table is cached. The system searches for data in the cache each time a data record is read from the source table. If the data is not found, the system searches for the data in the physical dimension table. If you set the lookup.cache.strategy parameter to LRU, you must configure the lookup.cache.max-rows parameter. ALL: indicates that all the data in the dimension table is cached. Before the system runs a job, the system loads all data in the dimension table to the cache. This way, the cache is searched for all subsequent queries in the dimension table. If the system does not find the data record in the cache, the join key does not exist. The system reloads all data in the cache after cache entries expire. If the amount of data in a remote table is small and a large number of missing keys exist, Ververica recommends that you set this parameter to ALL. The source table and dimension table cannot be associated based on the ON clause. Important:. 1. If you set the lookup.cache.strategy parameter to ALL, you must monitor the memory usage of the node to prevent out of memory (OOM) errors.. 2. If you set the lookup.cache.strategy parameter to ALL, you must increase the memory of the node for joining tables because the system asynchronously loads data from the dimension table. The increased memory size is twice that of the remote table. |
| lookup.cache.max-rows | The maximum number of data records that can be cached. | N | INTEGER | N/A. | You must configure this parameter if the lookup.cache.strategy parameter is set to LRU. You do not need to configure this parameter if the lookup.cache.strategy parameter is set to ALL. |
| lookup.cache.ttl | The cache timeout period. | N | DURATION | N/A. | The setting of the lookup.cache.ttl parameter is related to the lookup.cache.strategy parameter. If you set the lookup.cache.strategy parameter to None, you do not need to configure the lookup.cache.ttl parameter. This indicates that cache entries do not expire. If you set the lookup.cache.strategy parameter to LRU, the lookup.cache.ttl parameter indicates the cache timeout period. By default, cache entries do not expire. If you set the lookup.cache.strategy parameter to ALL, the lookup.cache.ttl parameter indicates the cache refresh period. By default, the cache is not refreshed. |
Unique to result table
| Parameter | Description | Required | Type | Default | Note |
|---|---|---|---|---|---|
| sink.max-retries | The maximum number of retries to write data to the table after data fails to be written. | N | INTEGER | 3 | N/A. |
| sink.buffer-flush.max-rows | The maximum number of data records that can be cached in the memory. | N | INTEGER | 100 | N/A. |
| sink.buffer-flush.interval | The interval at which the cache is cleared. This value indicates that if the number of cached data records does not reach the upper limit in a specified period of time, all cached data is written to the result table. | N | DURATION | 1 second | N/A. |
Data type mappings
CDC source table
| Data type of MySQL CDC | Data type of Flink |
|---|---|
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| TINYINT UNSIGNED | SMALLINT |
| TINYINT UNSIGNED ZEROFILL | SMALLINT |
| INT | INT |
| MEDIUMINT | INTINT |
| SMALLINT UNSIGNED | INT |
| SMALLINT UNSIGNED ZEROFILL | INT |
| BIGINT | BIGINT |
| INT UNSIGNED | BIGINT |
| INT UNSIGNED ZEROFILL | BIGINT |
| MEDIUMINT UNSIGNED | BIGINT |
| MEDIUMINT UNSIGNED ZEROFILL | BIGINT |
| BIGINT UNSIGNED | DECIMAL(20, 0) |
| BIGINT UNSIGNED ZEROFILL | DECIMAL(20, 0) |
| SERIAL | DECIMAL(20, 0) |
| FLOAT [UNSIGNED] [ZEROFILL] | FLOAT |
| DOUBLE [UNSIGNED] [ZEROFILL] | DOUBLE |
| DOUBLE PRECISION [UNSIGNED] [ZEROFILL] | DOUBLE |
| REAL [UNSIGNED] [ZEROFILL] | DOUBLE |
| NUMERIC(p, s) [UNSIGNED] [ZEROFILL] | DECIMAL(p, s) |
| DECIMAL(p, s) [UNSIGNED] [ZEROFILL] | DECIMAL(p, s) |
| BOOLEAN | BOOLEAN |
| TINYINT(1) | BOOLEAN |
| DATE | DATE |
| TIME [(p)] | TIME [(p)] [WITHOUT TIMEZONE] |
| DATETIME [(p)] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
| TIMESTAMP [(p)] | TIMESTAMP [(p)] |
| TIMESTAMP [(p)] | TIMESTAMP [(p)] WITH LOCAL TIME ZONE |
| CHAR(n) | STRING |
| VARCHAR(n) | STRING |
| TEXT | STRING |
| BINARY | BYTES |
| VARBINARY | BYTES |
| BLOB | BYTES |
Dimension table and result table
| Data type of MySQL CDC | Data type of Flink |
|---|---|
| TINYINT | TINYINT |
| SMALLINT | SMALLINT |
| TINYINT UNSIGNED | SMALLINT |
| INT | INT |
| MEDIUMINT | INT |
| SMALLINT UNSIGNED | INT |
| BIGINT | BIGINT |
| INT UNSIGNED | BIGINT |
| BIGINT UNSIGNED | DECIMAL(20, 0) |
| FLOAT | FLOAT |
| DOUBLE | DOUBLE |
| DOUBLE PRECISION | DOUBLE |
| NUMERIC(p, s) | DECIMAL(p, s) |
| DECIMAL(p, s) | DECIMAL(p, s) |
| BOOLEAN | BOOLEAN |
| TINYINT(1) | BOOLEAN |
| DATE | DATE |
| TIME [(p)] | TIME [(p)] [WITHOUT TIMEZONE] |
| DATETIME [(p)] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
| TIMESTAMP [(p)] | TIMESTAMP [(p)] [WITHOUT TIMEZONE] |
| CHAR(n) | CHAR(n) |
| VARCHAR(n) | VARCHAR(n) |
| BIT(n) | BINARY(⌈n/8⌉) |
| BINARY(n) | BINARY(n) |
| VARBINARY(N) | VARBINARY(N) |
| TINYTEXT | STRING |
| TEXT | STRING |
| MEDIUMTEXT | STRING |
| LONGTEXT | STRING |
| TINYBLOB | BYTES. Flink supports only MySQL binary large object (BLOB) records that are less than or equal to 2,147,483,647(2^31 - 1). |
| BLOB | BYTES. Flink supports only MySQL binary large object (BLOB) records that are less than or equal to 2,147,483,647(2^31 - 1). |
| MEDIUMBLOB | BYTES. Flink supports only MySQL binary large object (BLOB) records that are less than or equal to 2,147,483,647(2^31 - 1). |
| LONGBLOB | BYTES. Flink supports only MySQL binary large object (BLOB) records that are less than or equal to 2,147,483,647(2^31 - 1). |
More about MySQL CDC Source
Principles
A MySQL CDC source table is a streaming source table of MySQL databases. A MySQL CDC source table reads full historical data from a database and then reads data from binary log files. This way, data accuracy is ensured. If an error occurs, the exactly-once semantics can be used to ensure data accuracy. You can run multiple deployments at the same time to read full data from a MySQL CDC source table by using the MySQL CDC connector. When the deployments are running, the incremental snapshot algorithm is used to perform lock-free reading and resumable uploads.
The MySQL CDC source table provides the following features.
-
Integrates stream processing and batch processing to support full and incremental data reading. This way, you do not need to separately implement stream processing and batch processing.
-
Allows you to run multiple deployments at the same time to read full data from a MySQL CDC source table. This way, data can be read in a more efficient manner.
-
Seamlessly switches between full and incremental data reading and supports automatic scale-in operations. This reduces computing resources that are consumed.
-
Supports resumable uploads during full data reading. This way, data can be uploaded in a more stable manner.
-
Reads full data without locks. This way, online business is not affected.
When a Ververica Cloud deployment starts, the MySQL CDC connector scans the full table and splits the table into multiple chunks based on the primary key. Then, the MySQL CDC connector uses the incremental snapshot algorithm to read the data from each chunk. The deployment periodically generates checkpoints to record the chunks whose data is read. If a failover occurs, the MySQL CDC connector needs to only continue reading data from the chunks whose data is not read. After the data of all chunks is read, incremental change records are read from the previously obtained binary log file position. The deployment continues periodically generating checkpoints to record the binary log file position. If a failover occurs, the MySQL CDC connector processes data from the previous binary log file position. This way, the exactly-once semantics is implemented. For more information about the incremental snapshot algorithm, see MySQL CDC Source .
Metadata
In most cases, access to metadata is required when you merge and synchronize tables in a sharded database. If you expect to identify data records by the source database names and table names after tables are merged, you can configure metadata columns in the data merging statement to read the source database name and table name of each data record. This way, you can identify the source of each data record after tables are merged.
The following table describes the metadata that you can access by using metadata columns.
| Metadata key | Metadata type | Description |
|---|---|---|
| database_name | STRING NOT NULL | The name of the source database to which the current data record belongs. |
| table_name | STRING NOT NULL | The name of the source table to which the current data record belongs. |
| op_ts | TIMESTAMP_LTZ(3) NOT NULL | The time when the current data record changes in the database. If the data record is obtained from the historical data of the table instead of from the binary log file, the value of the metadata key is fixed to 0. |
The following sample code shows how to merge multiple orders tables in database shards of a MySQL instance into a MySQL table named mysql_orders and synchronize data from the MySQL table to a print table named print_orders.
CREATE TABLE mysql_orders (
db_name STRING METADATA FROM 'database_name' VIRTUAL, -- Read the database name.
table_name STRING METADATA FROM 'table_name' VIRTUAL, -- Read the table name.
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL, -- Read the change time.
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'flinkuser',
'password' = 'flinkpw',
'database-name' = 'mydb_.*', -- Use a regular expression to match multiple database shards.
'table-name' = 'orders_.*' -- Use a regular expression to match multiple tables in the sharded database.
);
INSERT INTO print_orders SELECT * FROM mysql_orders;
Support for regular expressions
MySQL CDC source table supports the use of regular expressions in database names and table names to match multiple databases and tables. The code example for specifying multiple tables by regular expression is as follows.
CREATE TABLE products (
db_name STRING METADATA FROM 'database_name' VIRTUAL,
table_name STRING METADATA FROM 'table_name' VIRTUAL,
operation_ts TIMESTAMP_LTZ(3) METADATA FROM 'op_ts' VIRTUAL,
order_id INT,
order_date TIMESTAMP(0),
customer_name STRING,
price DECIMAL(10, 5),
product_id INT,
order_status BOOLEAN,
PRIMARY KEY(order_id) NOT ENFORCED
) WITH (
'connector' = 'mysql-cdc',
'hostname' = 'localhost',
'port' = '3306',
'username' = 'root',
'password' = '123456',
'database-name' = '(^(test).*|^(tpc).*|txc|.*[p$]|t{2})', -- Match multiple databases
'table-name' = '(t[5-8]|tt)' -- Match multiple tables
);
The regular expression interpretation in the above example:
^(test).*is an example of prefix matching. This expression can match the database name beginning withtest, such astest1ortest2.*[p$]is an example of suffix matching. This expression can match database names ending inp, such ascdcporedcp.txcis a specified match, which can match the database name of the specified nametxc.
When MySQL CDC source table matches the full path table name, it will uniquely determine a table through the database name and table name, that is, use database-name.table-name as the matching table pattern. For example, matching pattern (^(test).|^ (tpc).|txc|.*[p$]|t{2}).(t[ 5-8]|tt) can match the tables txc.tt and test2.test5.
table-name and database-name support specifying multiple tables or databses separated by commas, such as 'table-name' = 'mytable1,mytable2'. However, it conflicts with the comma in the regular expression. If a regular expression containing a comma is used, the regular expression needs to be rewritten into the form of a vertical bar (|). For example, mytable_\d{1, 2) requires to use the equivalent regular expression (mytable_\d{1}|mytable_\d{2}) to avoid the usage of commas.
Parallelism control
The MySQL CDC connector can run multiple deployments at the same time to read full data. This improves the data loading efficiency. If you use the MySQL CDC connector with the Autopilot feature that is provided by Ververica Cloud, automatic scale-in can be performed during incremental data reading after parallel reading is complete. This saves computing resources.
You can configure the Parallelism parameter in Basic mode in the Resource Configuration panel.
When you configure the Parallelism parameter in Basic mode, make sure that the range specified by server-id in the table is greater than or equal to the value of the Parallelism parameter. For example, if the range of server-id is 5404-5412, eight unique server IDs can be used. Therefore, you can configure a maximum of eight parallel deployments. In addition, the range specified by server-id for the same MySQL instance in different deployments cannot overlap. Each deployment must be explicitly configured with a unique server ID.
Automatic scale-in by using Autopilot
When full data is read, a large amount of historical data is accumulated. In most cases, Ververica Cloud reads historical data in parallel to improve reading efficiency. When incremental data is read, only a single deployment is required to read data because the amount of binary log data is small and the global order must be ensured. The numbers of compute units (CUs) that are required during full data reading and incremental data reading are different. You can use the Autopilot feature to balance performance and resource consumption.
Autopilot monitors the traffic for each task that is used by the MySQL CDC source table. If the binary log data is read in only one task and other tasks are idle during incremental data reading, Autopilot automatically reduces the number of CUs and the parallelism. To enable Autopilot, you need only to set the Mode parameter of Autopilot to Active on the Deployments page.
By default, the minimum interval at which the decrease of the parallelism is triggered is set to 24 hours.
Startup mode
Specify the startup mode of the MySQL CDC source table by the configuration scan.startup.mode. Valid values include:
initial: When the MySQL CDC connector starts for the first time, Ververica Cloud scans all historical data and reads the most recent binary log data. This is the default value.latest-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the most recent offset, instead of scanning all historical data. This way, Ververica Cloud reads only the most recent incremental data after the connector starts.earliest-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the earliest offset, instead of scanning all historical data.specific-offset: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the specific offset, instead of scanning all historical data. Specify to start from a specific Binlog file name and offset byscan.startup.specific-offset.fileandscan.startup.specific-offset.pos. Specify to start from a specific GTID set byscan.startup.specific-offset.gtid-set.timestamp: When the MySQL CDC connector starts for the first time, Ververica Cloud reads binary log data from the specific timestamp, instead of scanning all historical data. The timestamp is specified byscan.startup.timestamp-millisin milliseconds.
Example usage:
CREATE TABLE specific_binlog_offset (...)
WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'specific-offset',
'scan.startup.specific-offset.file' = 'mysql-bin.000003',
'scan.startup.specific-offset.pos' = '4',
...
);
CREATE TABLE specific_gtid (...)
WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'specific-offset',
'scan.startup.specific-offset.gtid-set' = '24DA167-0C0C-11E8-8442-00059A3C7B00:1-19',
...
);
CREATE TABLE specific_timestamp (...)
WITH (
'connector' = 'mysql-cdc',
'scan.startup.mode' = 'timestamp',
'scan.startup.timestamp-millis' = '1667232000000'
...
);
- MySQL CDC source table will log the current position at the INFO level during checkpoint, and the log prefix is
Binlog offset on checkpoint {checkpoint-id}, which can help you to start the job from a certain checkpoint position. - If the read table has ever had a table schema change, an error may occur when starting from the earliest point (earliest-offset), specific point (specific-offset) or timestamp (timestamp). Because the Debezium reader will internally save the current latest table structure, the earlier data that does not match the schema cannot be parsed correctly.
FAQ
If the Flink job failed to start and the root cause of exception is:
Caused by: javax.net.ssl.SSLHandshakeException: No appropriate protocol (protocol is disabled or cipher suites are inappropriate)
try to add 'jdbc.properties.useSSL' = 'false' to connector’s parameters.
For example:
CREATE TEMPORARY TABLE MysqlTable (
id BIGINT,
name VARCHAR(128),
PRIMARY KEY (id) NOT ENFORCED
) WITH (
'connector' = 'mysql',
'hostname' = 'xxx',
'port' = 'xxx',
'database-name' = 'xxx',
'table-name' = 'xxx',
'username' = 'xxx',
'password' = 'xxx',
'jdbc.properties.useSSL' = 'false'
);