Dynamic Flink CEP
Ververica Cloud enables you to execute complex event processing (CEP) with Flink, which supports on-the-fly rule modifications using DataStream operations. This article explains how to create a Flink CEP setup that can automatically load updated rules to handle data from upstream Kafka, all while using a fully managed Flink environment.
Background information
Advertisers typically allocate budgets when they display ads on e-commerce sites. Consider a scenario where an advertiser's ad cost is determined by the number of ad clicks. If this advertiser falls victim to fraudulent online traffic, their budget will deplete rapidly, causing the ad to be taken down sooner than planned. This not only jeopardizes the advertiser's interests but might also lead to future grievances and disagreements.
To counteract these types of attacks, it's crucial to swiftly pinpoint malicious traffic and implement countermeasures, like barring deceitful users or alerting the advertisers, to safeguard user rights and interests. Moreover, unforeseen variables, such as endorsements from celebrities or viral trends, can trigger abrupt shifts in traffic. In these instances, the rules that discern malicious traffic need to be flexibly adjusted to prevent unintentional harm to genuine users.
This section explains the use of dynamic Flink CEP to address the challenges mentioned above. Here, user behavior logs are retained in an Amazon MSK for Kafka system. A Flink CEP system is tailored to process this Kafka data. To achieve this, the Flink CEP system checks the rule table in the Amazon RDS for MySQL database periodically, retrieves the most recent rules set by policy creators, and then employs these rules for event matching. Depending on the events that align with these rules, the Flink CEP system either sends alerts or logs pertinent details into other databases. The diagram below depicts the data flow for this case.
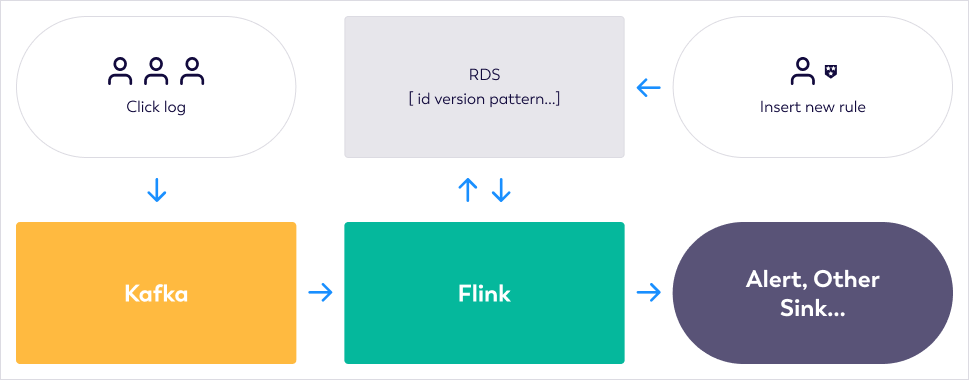
Prerequisites
You have created upstream and downstream storage instances.
- Amazon MSK
- Amazon RDS for MySQL
Step 1: Prepare test data
Create an upstream Kafka topic
Create an upstream Kafka topic named demo_topic to store simulated user behavior logs in your Amazon MSK.
Prepare an Amazon RDS for MySQL database
Create a rule table named rds_demo to record the rules that you want to use in your Flink CEP deployment. Run the SQL statements on Amazon RDS:
CREATE DATABASE cep_demo_db;
USE cep_demo_db;
CREATE TABLE rds_demo (
`id` VARCHAR(64),
`version` INT,
`pattern` VARCHAR(4096),
`function` VARCHAR(512)
);
Step 2: Configure the Amazon RDS for MySQL with “0.0.0.0/0” whitelist
Step 3: Develop a Flink CEP Java project for the deployment
Note: All the code discussed in this article is available for download from GitHub repository.
This section shows example code snippets to help guide your own Flink CEP project.
- Create a new Java project with Maven as the build tool.
- Add flink-cep as a project dependency in your Flink CEP demo project's pom.xml:
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-cep</artifactId>
<version>{insert-version}</version>
<scope>provided</scope>
</dependency>
Note: Remmber to replace the insert-version variable.
You can find the latest release versions on the Ververica JFrog Artifactory.
- Create a Kafka source and configure the CEP.dynamicPatterns() method. Here's the syntax:
public static <T, R> SingleOutputStreamOperator<R> dynamicPatterns(
DataStream<T> input,
PatternProcessorDiscovererFactory<T> discovererFactory,
TimeBehaviour timeBehaviour,
TypeInformation<R> outTypeInfo)
| Parameter | Description |
|---|---|
DataStream<T> input | The input event stream. |
PatternProcessorDiscovererFactory<T> discovererFactory | The factory object. The factory object constructs a PatternProcessorDiscoverer interface that is used to obtain the most recent rules. In this case, a PatternProcessor interface is constructed. |
TimeBehaviour timeBehaviour | The time attribute that defines how the Flink CEP deployment processes events. |
| TimeBehaviour.ProcessingTime: specifies that events are processed based on the processing time. | |
| TimeBehaviour.EventTime: specifies that events are processed based on the event time. | |
TypeInformation<R> outTypeInfo | The type information of the output stream. |
For an in-depth understanding of Flink deployment’s standard concepts like DataStream, TimeBehaviour, and TypeInformation, refer to the Flink DataStream API Programming Guide, the article on Notions of Time: Event Time and Processing Time, and the Class TypeInformation <T> documentation.
This segment delves into the PatternProcessor interface. The PatternProcessor interface comprises a Pattern method, which outlines the criteria for event-pattern matching, and a PatternProcessFunction method, detailing the steps post-matching — for instance, dispatching alert notifications. Additionally, fields like id and version are present for uniquely pinpointing the crafted pattern processor. Essentially, a PatternProcessor interface formulates a rule and delineates the Flink CEP deployment’s reaction upon its activation. To delve deeper, consult FLIP-200: Support Multiple Rule and Dynamic Rule Changing (Flink CEP).
The PatternProcessorDiscovererFactory interface plays a role in crafting a PatternProcessorDiscoverer interface, which fetches updates for the pattern processor. In the presented instance, a standard abstract class is deployed to scan external storage at regular intervals. The sample code provided below demonstrates initiating a timer for consistent external storage checks, aiming to retrieve pattern processor updates:
public abstract class PeriodicPatternProcessorDiscoverer<T>
implements PatternProcessorDiscoverer<T> {
...
@Override
public void discoverPatternProcessorUpdates(
PatternProcessorManager<T> patternProcessorManager) {
// Periodically discovers the pattern processor updates.
timer.schedule(
new TimerTask() {
@Override
public void run() {
if (arePatternProcessorsUpdated()) {
List<PatternProcessor<T>> patternProcessors = null;
try {
patternProcessors = getLatestPatternProcessors();
} catch (Exception e) {
e.printStackTrace();
}
patternProcessorManager.onPatternProcessorsUpdated(patternProcessors);
}
}
},
0,
intervalMillis);
}
...
}
Ververica Cloud offers the JDBCPeriodicPatternProcessorDiscoverer interface, enabling retrieval of the latest rules from databases compatible with the Java Database Connectivity (JDBC) protocol. Below is a table detailing the parameters necessary when utilizing this interface:
| Parameter | Description |
|---|---|
jdbcUrl | The JDBC URL that you can use to connect to the database. |
jdbcDriver | The name of the database driver class. |
tableName | The name of the table in the database. |
initialPatternProcessors | The pattern processor updates that are pulled from the database. If the rule table in the database is empty, the default pattern processor is used. |
intervalMillis | The interval at which the database is polled. |
The following sample code provides an example. In this example, the events matched by the Flink CEP deployment are displayed in the TaskManager logs of Flink.
// import ......
public class CepDemo {
public static void main(String[] args) throws Exception {
......
// DataStream Source
DataStreamSource<Event> source =
env.fromSource(
kafkaSource,
WatermarkStrategy.<Event>forMonotonousTimestamps()
.withTimestampAssigner((event, ts) -> event.getEventTime()),
"Kafka Source");
env.setParallelism(1);
// keyBy userId and productionId
// Notes, only events with the same key will be processed to see if there is a match
KeyedStream<Event, Tuple2<Integer, Integer>> keyedStream =
source.keyBy(
new KeySelector<Event, Tuple2<Integer, Integer>>() {
@Override
public Tuple2<Integer, Integer> getKey(Event value) throws Exception {
return Tuple2.of(value.getId(), value.getProductionId());
}
});
SingleOutputStreamOperator<String> output =
CEP.dynamicPatterns(
keyedStream,
new JDBCPeriodicPatternProcessorDiscovererFactory<>(
JDBC_URL, JDBC_DRIVE, TABLE_NAME, null, JDBC_INTERVAL_MILLIS),
TimeBehaviour.ProcessingTime,
TypeInformation.of(new TypeHint<String>() {}));
output.print();
// Compile and submit the job
env.execute("CEPDemo");
}
}
In the demo code, the CEP.dynamicPatterns() method is added to split input data streams into different partitions based on the userId and productionId parameters. This way, only events that have the same values of the userId and productionId parameters are matched based on the rules. Events that have different key values are not matched.
- Create a JAR file of your CEP demo project.
You should now build and create a uber JAR file of your CEP demo project. For that you can run the following maven command in the project root directory:
mvn clean verify
The final JAR file is located at target/cep-demo-VERSION.jar.
The following table describes the parameters that you need to configure when you create a deployment.
In this example, no data is stored in the upstream Kafka source, and the rule table in the database is empty. Therefore, no output is returned after you run the deployment.
| Parameter | Description |
|---|---|
| Deployment Type | Select JAR. |
| Deployment Name | Enter the name of the JAR deployment that you want to create. |
| Engine Version | Select an engine version |
| JAR URL | Upload your JAR file or the test JAR file. |
| Entry Point Class | Set the value to com.ververica.cep.demo.CepDemo. |
| Entry Point Main Arguments | Adapt the arguments depending on your CEP project. If you are using a Ververica cep-demo built JAR file, use the following parameters: |
-kafkaBrokers YOUR_KAFKA_BROKERS | |
-inputTopic YOUR_KAFKA_TOPIC | |
-inputTopicGroup YOUR_KAFKA_TOPIC_GROUP | |
-jdbcUrl jdbc:mysql://YOUR_DB_URL:port/DATABASE_NAME?user=YOUR_USERNAME&password=YOUR_PASSWORD | |
-tableName YOUR_TABLE_NAME | |
-jdbcIntervalMs 3000 | |
| Parameters | kafkaBrokers: the addresses of Kafka brokers. |
inputTopic: the name of the Kafka topic. | |
inputTopicGroup: the consumer group of Kafka. | |
jdbcUrl: the JDBC URL of the database. Note: Ensure the JDBC URL username and password are standard, with the password containing only letters and digits. Modify the parameters as per your storage instance details. Avoid exceeding 1024 characters for parameter values. If necessary, use a dependency file for complex parameters. | |
tableName: the name of the destination table. | |
jdbcIntervalMs: the interval at which the database is polled. Note: You must change the values of the preceding parameters based on the information about the upstream and downstream storage instances. A parameter value cannot be greater than 1024 characters in length. Ververica recommends that you do not use complex parameters. A parameter whose value includes line breaks, spaces, or other special characters is considered a complex parameter. A parameter value can contain only letters and digits. If you want to pass complex parameters, use a dependency file. |
- In the Configuration tab on the Deployments page, scroll down to Parameters section and click Edit. Enter the following code in the Other Configuration field:
kubernetes.application-mode.classpath.include-user-jar: 'true'
classloader.resolve-order: parent-first
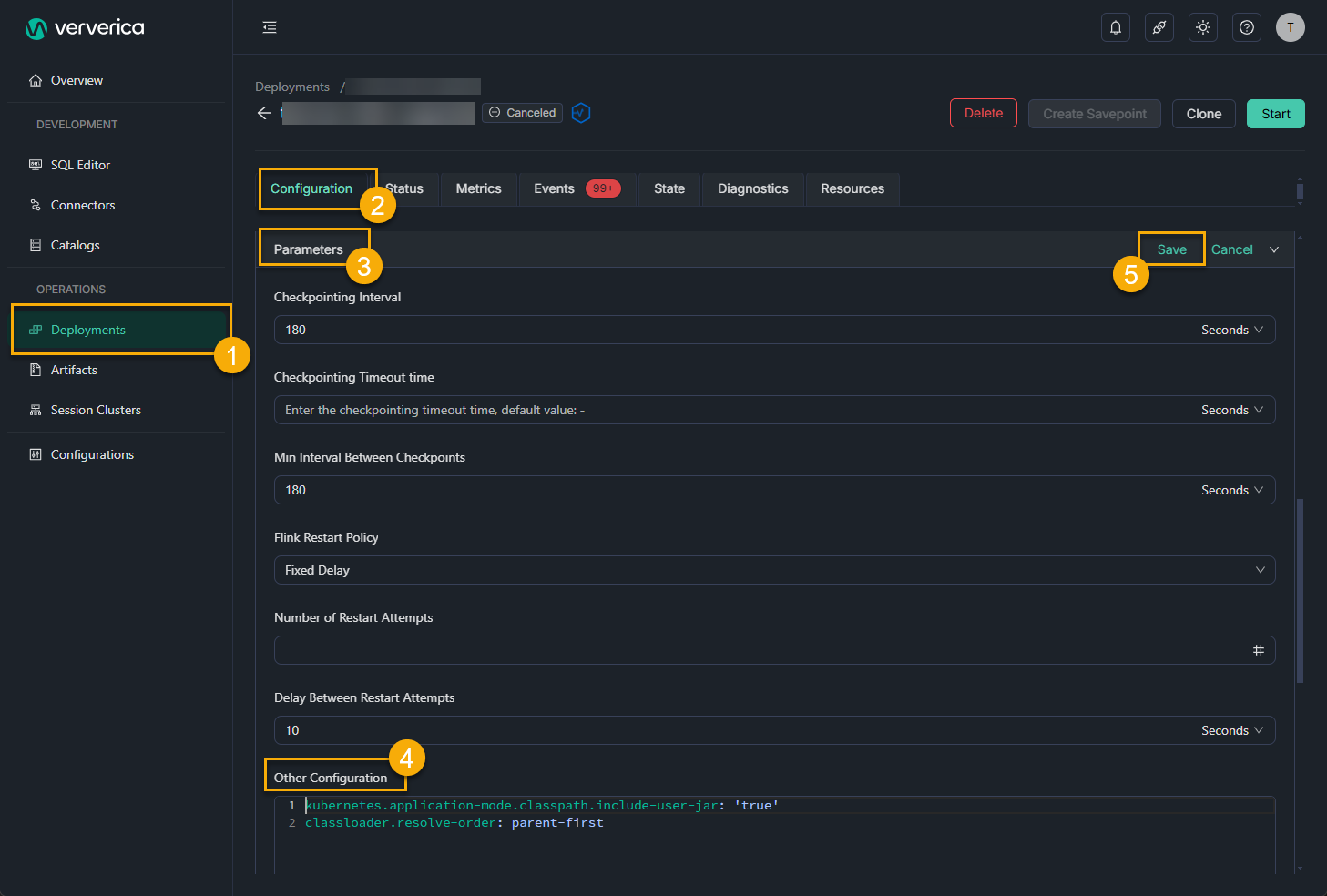
- On the Deployments page in the console, find the desired deployment and click Start in the Actions column.
Step 4: Add a rule
Once the Flink CEP deployment is initiated, implement version 1 of Rule 1: When three successive events have an action value of 0, and the subsequent event does not have an action value of 1, it signifies that there hasn’t been a purchase even after three continuous product visits.
- Add a rule that is dynamically updated in Amazon RDS for MySQL
Merge the JSON string that defines a rule with the field names such as id, version, and function, and then execute the INSERT INTO statement to insert data into the rule table in the RDS for MySQL database.
INSERT INTO rds_demo (
`id`,
`version`,
`pattern`,
`function`
) values(
'1',
1,
'{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}',
'com.ververica.cep.demo.dynamic.DemoPatternProcessFunction'
);
For clearer readability of the pattern field in a database, we have outlined a series of rule descriptions in JSON format. For detailed insights, refer to definitions of rules in the JSON format. The pattern field value in the mentioned SQL statement stands as a serialized pattern string of a rule depicted in JSON format. Essentially, this string is designed to capture a specific pattern: When three successive events carry an action value of 0, the following event also does not present an action value of 1.
The EndCondition parameter in the following code defines that the action value of the next event is still not 1.
- The following code shows the syntax of the Pattern method:
Pattern<Event, Event> pattern =
Pattern.<Event>begin("start", AfterMatchSkipStrategy.skipPastLastEvent())
.where(new StartCondition("action == 0"))
.timesOrMore(3)
.followedBy("end")
.where(new EndCondition());
- The following sample code provides an example of the JSON string that defines a rule:
{
"name": "end",
"quantifier": {
"consumingStrategy": "SKIP_TILL_NEXT",
"properties": ["SINGLE"],
"times": null,
"untilCondition": null
},
"condition": null,
"nodes": [
{
"name": "end",
"quantifier": {
"consumingStrategy": "SKIP_TILL_NEXT",
"properties": ["SINGLE"],
"times": null,
"untilCondition": null
},
"condition": {
"className": "com.ververica.cep.demo.condition.EndCondition",
"type": "CLASS"
},
"type": "ATOMIC"
},
{
"name": "start",
"quantifier": {
"consumingStrategy": "SKIP_TILL_NEXT",
"properties": ["LOOPING"],
"times": {
"from": 3,
"to": 3,
"windowTime": null
},
"untilCondition": null
},
"condition": {
"expression": "action == 0",
"type": "AVIATOR"
},
"type": "ATOMIC"
}
],
"edges": [
{
"source": "start",
"target": "end",
"type": "SKIP_TILL_NEXT"
}
],
"window": null,
"afterMatchStrategy": {
"type": "SKIP_PAST_LAST_EVENT",
"patternName": null
},
"type": "COMPOSITE",
"version": 1
}
- Use a Kafka client to send messages to the demo_topic topic.
1,Ken,0,1,1662022777000
1,Ken,0,1,1662022778000
1,Ken,0,1,1662022779000
1,Ken,0,1,1662022780000
The following table describes the fields of messages in the demo_topic topic.
| Field | Description |
|---|---|
id | The ID of the user. |
username | The name of the user. |
action | The action of the user. Valid values: |
| - 0: the view operation. | |
| - 1: the purchase operation. | |
| - 2: the share operation. | |
product_id | The ID of the product. |
event_time | The event time when the action was performed. |
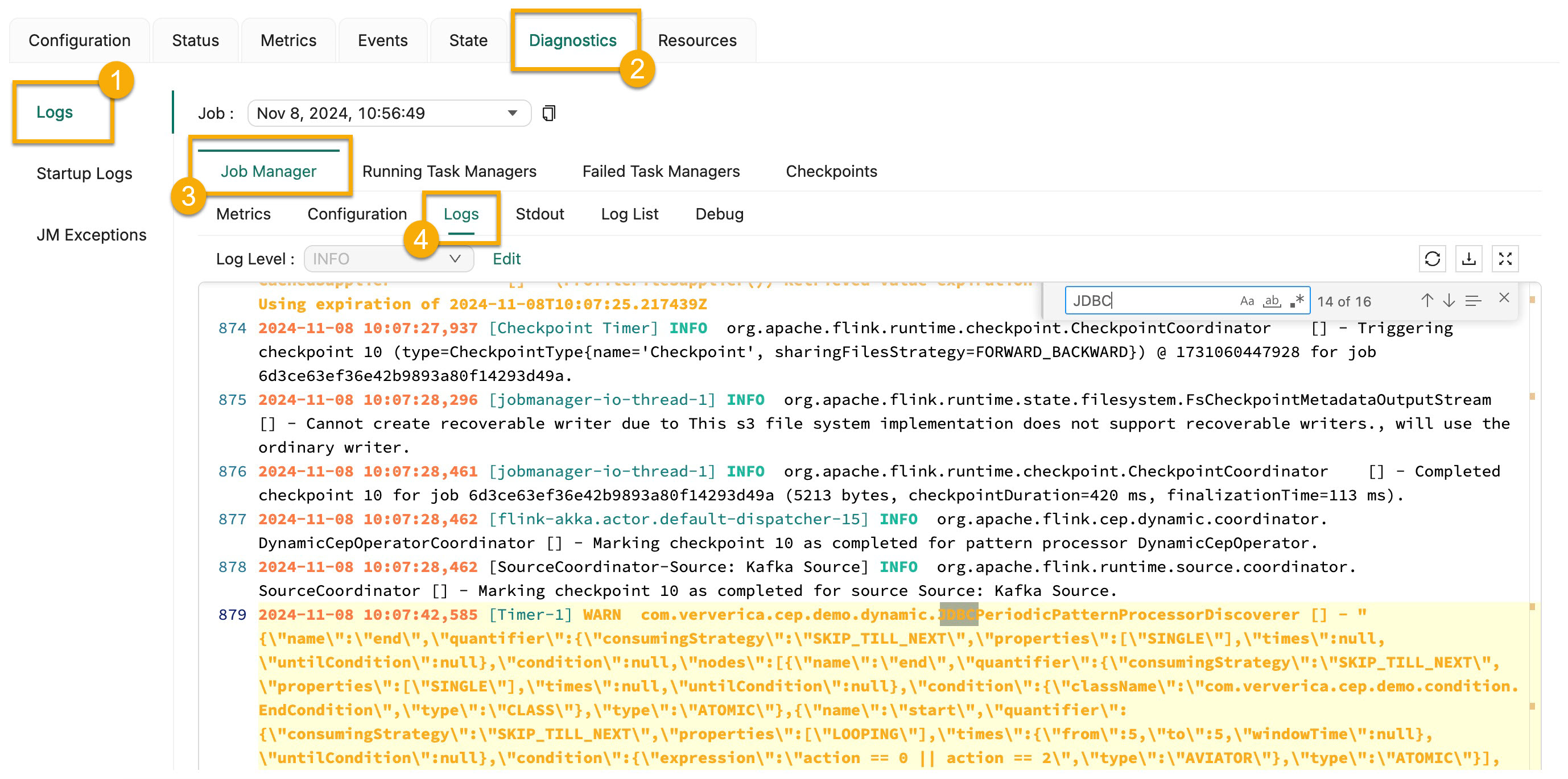
- View the most recent rule that is displayed in the JobManager logs and the matching results displayed in the TaskManager logs.
- On the Logs tab of the Job Manager tab, use the keyword JDBCPeriodicPatternProcessorDiscoverer to search for the most recent rule.
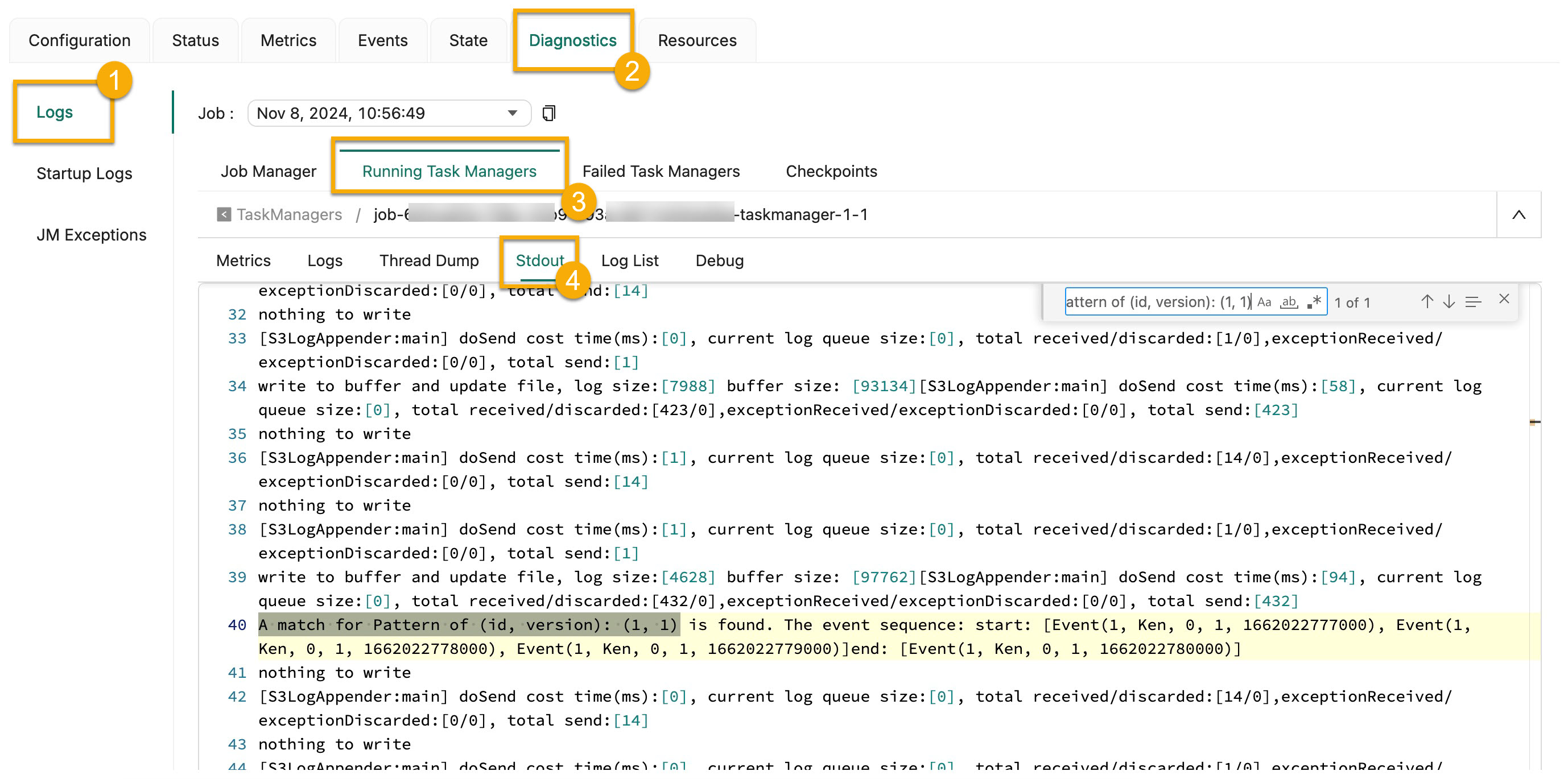
- On the Log List tab of the Running Task Managers tab, find the log file whose name ends with .out and use the A match for Pattern of (id, version): (1, 1) keyword to search for the matching results.
Step 5: Update the matching rules and check whether the updated rules take effect
Once events have been matched and processed according to Rule 1, modify the pattern of Rule 1 to: Five successive events with the action value of either 0 or 2, followed by an event that doesn’t have an action value of 1. This adjustment addresses heightened traffic. Add Rule 2, which has a pattern identical to Rule 1’s original, to test capabilities like the support for multiple rules.
- Update the matching rules in Amazon RDS for MySQL
Change action == 0 in the value of the StartCondition parameter to action == 0 || action == 2, and change the two values of the times parameter from 3 to 5. This is version 2 of Rule 1. The following SQL statement provides an example.
INSERT INTO rds_demo(`id`, `version`, `pattern`, `function`)
values('1', 2, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":5,"to":5,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0 || action == 2","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.ververica.cep.demo.dynamic.DemoPatternProcessFunction');
Add a rule whose id value is 2 as Rule 2.
The SQL statement of Rule 2 is the same as that of version 1 of Rule 1. The StartCondition parameter is still set to action == 0, and the two values of the times parameter are 3 and 3.
INSERT INTO rds_demo(`id`, `version`, `pattern`, `function`)
values('2', 1, '{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":null,"nodes":[{"name":"end","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["SINGLE"],"times":null,"untilCondition":null},"condition":{"className":"com.ververica.cep.demo.condition.EndCondition","type":"CLASS"},"type":"ATOMIC"},{"name":"start","quantifier":{"consumingStrategy":"SKIP_TILL_NEXT","properties":["LOOPING"],"times":{"from":3,"to":3,"windowTime":null},"untilCondition":null},"condition":{"expression":"action == 0","type":"AVIATOR"},"type":"ATOMIC"}],"edges":[{"source":"start","target":"end","type":"SKIP_TILL_NEXT"}],"window":null,"afterMatchStrategy":{"type":"SKIP_PAST_LAST_EVENT","patternName":null},"type":"COMPOSITE","version":1}','com.ververica.cep.demo.dynamic.DemoPatternProcessFunction');
- Send eight simple messages to trigger a match in the Amazon MQ (Message Broker) for Kafka console.
The following eight messages provide an example:
1,Ken,0,1,1662022777000
1,Ken,0,1,1662022777000
1,Ken,0,1,1662022777000
1,Ken,2,1,1662022777000
1,Ken,0,1,1662022777000
1,Ken,0,1,1662022777000
1,Ken,0,1,1662022777000
1,Ken,2,1,1662022777000
On the Log List tab of the Running Task Managers tab, find the log file whose name ends with .out, and view the matching results.
- If you want to search for the matching results that are generated based on Version 2 of Rule 1, use the A match for Pattern of (id, version): (1, 2) keyword.
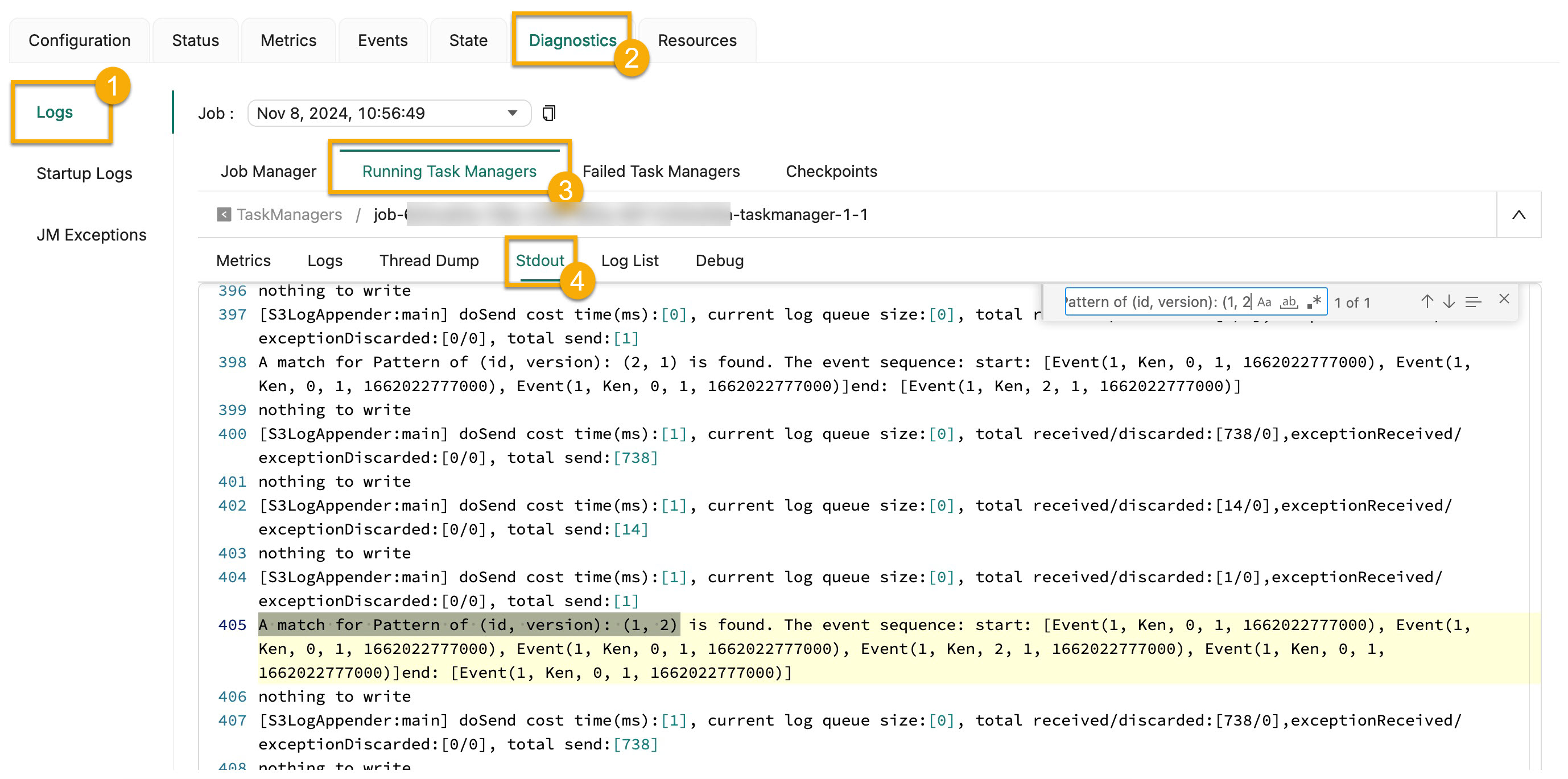
- If you want to search for the matching results that are generated based on Version 1 of Rule 2, use the A match for Pattern of (id, version): (2, 1) keyword.
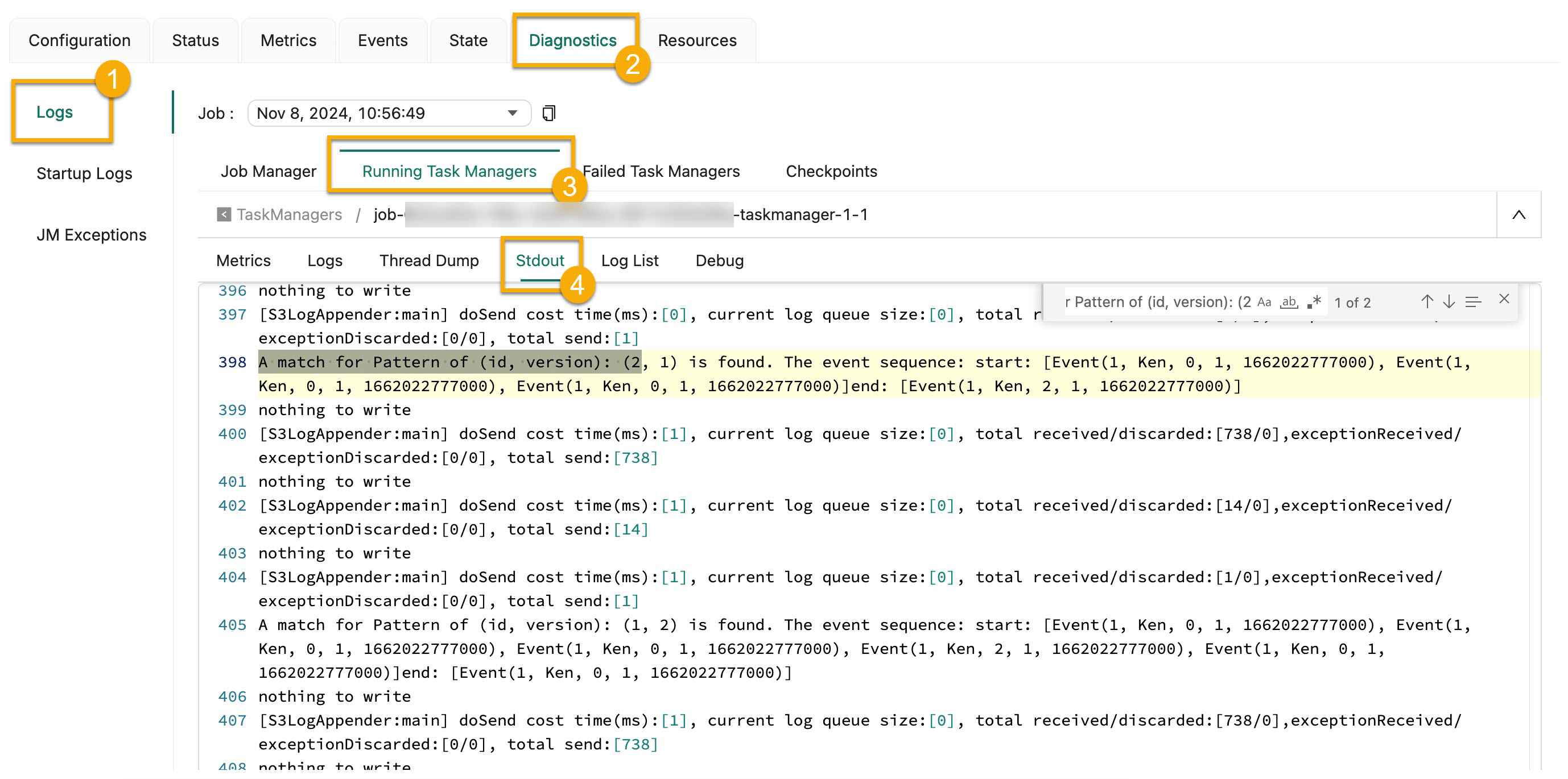
The previously presented figures depict the following match outcomes:
- According to Version 2 of Rule 1, the Flink CEP deployment identifies a series of events consisting of five successive actions with values of 0 or 2, followed by an action value different from 1. This confirms the successful implementation of the dynamically updated Rule 1.
- As per Version 1 of Rule 2, the Flink CEP deployment spots two event sequences, each comprising three consecutive actions with a value of 0, succeeded by an action with a value not equal to 1. This confirms the effective addition of the dynamically introduced Rule 2.