About The Ververica Ecosystem
The Ververica ecosystem empowers organizations with advanced tools for real-time data stream processing. The ecosystem includes a cohesive set of components, solutions, and integrations that enable users to deploy, manage, and optimize stream and batch processing workloads in cloud-native, hybrid, and on-premises environments.
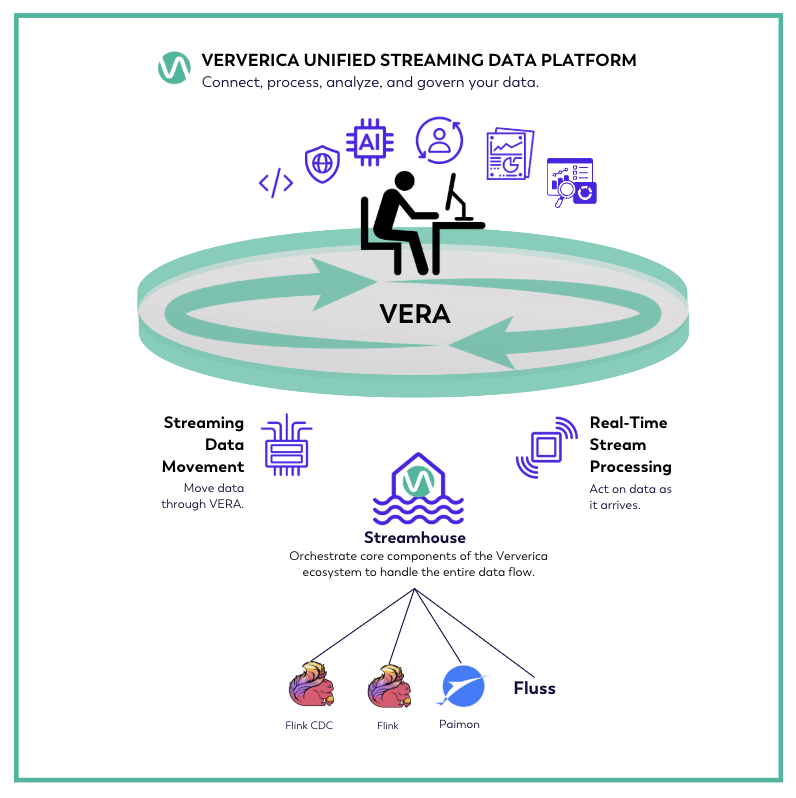
Core Ecosystem Components
The core components in the Ververica ecosystem include open-source adjacent software and enterprise components and tools.
- Ververica Unified Streaming Data Platform sits at the center of Ververica's ecosystem. The platform focuses on the features and components that enhance the development, deployment, and management of data streaming applications in the ecosystem.
- Apache Flink powers real-time and batch stream processing with stateful, scalable, and fault-tolerant capabilities, serving as the foundation for the platform. It supports both real-time and batch workloads and performs centralized stream processing powered by Flink's rich APIs (DataStream, SQL, Table API). Additionally, it democratizes access to streaming data with an interactive SQL interface, empowering analysts and engineers to query and transform data streams in real time.
- Apache Paimon acts as a unified storage layer for streaming and batch data, enabling efficient incremental updates and time travel queries for real-time and historical analytics.
- Flink CDC enables real-time change data capture from transactional databases, bridging operational systems and analytical pipelines for up-to-date insights.
- Fluss enhances Flink's state management by providing a scalable, stream-native storage solution, ensuring low-latency access, efficient checkpointing, and reliable state recovery for large-scale, stateful applications.
- Streamhouse unifies streaming and batch processing by integrating Apache Flink, Apache Paimon, Flink CDC, and Fluss to handle real-time data ingestion, processing, state management, and storage, enabling low-latency analytics and seamless querying of both real-time and historical data.
How the Core Components Work Together in the Ecosystem
The combination of technologies and tools enables integration, real-time and batch synergy, and operational efficiency within the Ververica ecosystem.
- Apache Paimon + Flink SQL provide a unified platform for querying real-time and historical data using SQL.
- Fluss + Ververica Unified Streaming Data Platform enhance stateful processing capabilities, making it easier to scale and operate Flink applications in production.
- Flink CDC + Connectors extend Flink’s reach by integrating with transactional systems, creating a real-time bridge between operational and analytical data layers.
- Apache Paimon + Flink CDC enable seamless bridging real-time data ingestion and batch data processing.
- Fluss + Flink CDC reduce the complexity of managing large stateful applications.
Streamhouse integrates these components to handle the entire data flow.

Streamhouse leverages Flink CDC to ingest real-time changes from database, routes them through Flink for processing, and then stores the processed data in Apache Paimon. This enables seamless transitions between real-time streaming workloads and batch analytics.
With Apache Paimon as the storage backbone, Streamhouse enables unified access to both real-time and historical datasets. Flink SQL allows users to query these datasets interactively, connecting data engineering and analytics workflows.
Fluss optimizes stateful operations in Flink by providing low-latency state management and efficient recovery. This strengthens the ability of Streamhouse to handle large-scale, real-time applications with dynamic state requirements.
Ververica Unified Streaming Data Platform integrates these components into a single operational layer, providing visibility and control over data ingestion, stateful stream processing, and storage. This reduces complexity and aligns with Ververica's vision of end-to-end simplicity.
You can also use each component (Flink for processing, Paimon for storage, Fluss for state management, and CDC for ingestion) independently. This modularity allows organizations to adopt features and capabilities of Ververica Unified Streaming Data Platform incrementally while maintaining interoperability with existing systems.
By integrating these tools, Streamhouse removes barriers between real-time and batch processing, enabling more flexible and efficient data architectures that support modern data-driven decision-making.
Related Topics
Learn more about the open-source adjacent software technologies and enterprise components and tools:
Learn more about Ververica Unified Streaming Data Platform and VERA's Core Pillars.
{kind=link}