FlinkSQL performance guide
Deployment configuration optimization
Optimize resource configurations
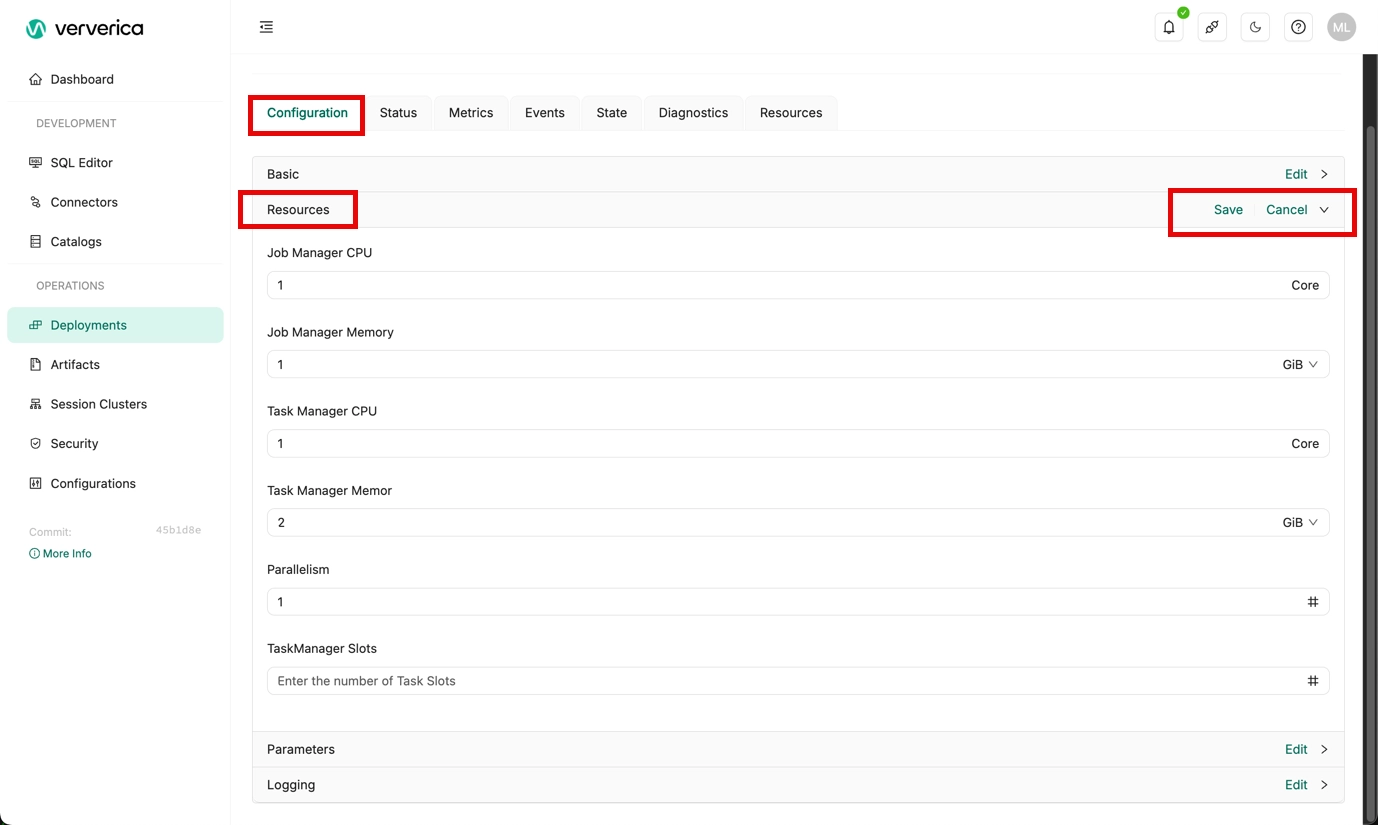
Ververica Cloud limits the actual usage size of CPU cores of JobManager and TaskManager, and only allows the maximum number of CPUs configured to be used. Therefore, when optimizing resources, it is recommended that you make the following changes to a deployment:
-
When job parallelism is large: you can edit the deployment's resources to increase the CPU cores and memory size used by the JobManager. For example:
- Set JobManager CPUs to 4.
- Set JobManager Memory to 8 GiB.
-
When the topology is complex: you can edit the deployment's resources to increase the CPU cores and memory size used by the TaskManager. For example:
- Set TaskManager CPUs to 2.
- Set TaskManager Memory to 4 GiB.
-
It is not recommended to modify taskmanager.numberOfTaskSlots, keep the default value of 1.
You make the above changes in the Deployments module. Select the deployment and click to Edit the Resources section of the Configuration tab.
Recommend configuration to improve throughput and address data skew
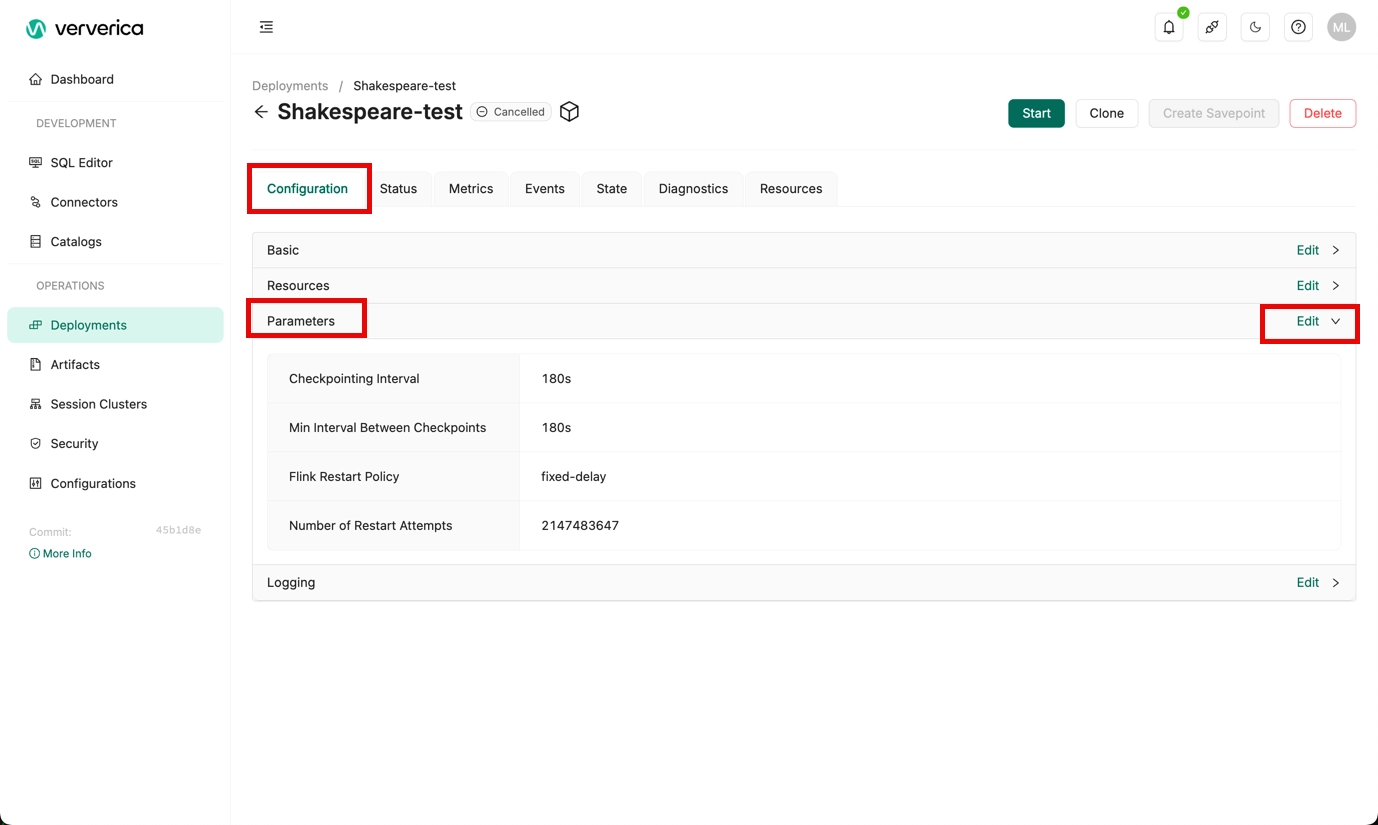
Add the following code to the Additional Configuration section on the Advanced tab. For more information, see Optimize Group Aggregate.
execution.checkpointing.interval: 180s
state.backend: com.ververica.flink.statebackend.GeminiStateBackendFactory
table.exec.state.ttl: 129600000
table.exec.mini-batch.enabled: true
table.exec.mini-batch.allow-latency: 5s
table.optimizer.distinct-agg.split.enabled: true
env.java.opts.taskmanager: -Xms4096m -XX:+UseParNewGC -XX:+UseCMSInitiatingOccupancyOnly -XX:CMSInitiatingOccupancyFraction=70 -verbose:gc -XX:+HeapDumpOnOutOfMemoryError -XX:+UseConcMarkSweepGC -XX:+UseCMSCompactAtFullCollection -XX:CMSMaxAbortablePrecleanTime=1000 -XX:+CMSClassUnloadingEnabled -XX:+PrintGCDetails -XX:+PrintGCDateStamps -XX:SurvivorRatio=5 -XX:ParallelGCThreads=4
You make the above changes in the Deployments module. Select the deployment and click to Edit the Parameters section of the Configuration tab.
The following table describes the parameters.
| Parameter | Description |
|---|---|
| execution.checkpointing.interval | The checkpoint interval, in milliseconds. |
| state.backend | The configuration of the state backend. |
| table.exec.state.ttl | The time-to-live of state data, in milliseconds. |
| table.exec.mini-batch.enabled | Specifies whether to enable miniBatch optimization. |
| table.exec.mini-batch.allow-latency | The interval at which data is collected and executed and executed in batches. |
| table.optimizer.distinct-agg.split.enabled | Whether to split distinct aggregation (e.g. COUNT(DISTINCT col)) into two level aggregations. This optimization is very useful when there is data skew in distinct aggregation and gives the ability to scale up the job. Default is false. |
| env.java.opts.taskmanager | Java options to start the JVM of the TaskManager with. |
Improve the performance configuration of the Streaming Join
The Streaming Join operator supports automatic inference and enables state key-value (KV) separation optimization in Ververica Cloud. After enabling state KV separation optimization, it can significantly improve the performance of Streaming Join jobs. The performance test results in typical scenarios show that the performance is improved by more than 40%.
You can configure the table.exec.join.kv-separate parameter to specify whether to enable the KV separation feature. Valid values:
- AUTO: The Flink engine will automatically enable the KV separation optimization based on the characteristics of the Streaming Join operator internally.
- FORCE: Enables KV separation optimization.
- NONE: Disables KV separation optimization.
The key-value separation feature takes effect only on GeminiStateBackend.
Optimize Group Aggregate
Enable MiniBatch to improve data throughput
MiniBatch caches a certain amount of data in operators before triggering processing in order to reduce access to State and improve throughput while reducing data output. Operators trigger the mini-batch processing when receiving a special mini-batch event. The events are inserted in the source according to the specified time intervals (usually in seconds).
Scenarios
Mini-batch processing is a tradeoff between high throughput and low latency. If you have extremely low latency requirements, it is not recommended to enable micro-batch processing. However, for aggregation scenarios, micro-batch processing can significantly improve system performance, and it is recommended to enable it.
How to enable miniBatch
The miniBatch feature is disabled by default. To enable this feature, you must enter the following code in the Other Configuration section of the Parameters tab.
table.exec.mini-batch.enabled: true
table.exec.mini-batch.allow-latency: 5s
The following table describes the parameters.
| Parameter | Description |
|---|---|
| table.exec.mini-batch.enabled | Specifies whether to enable MiniBatch. |
| table.exec.mini-batch.allow-latency | The maximum latency can be used for MiniBatch to buffer input records. MiniBatch is triggered at the allowed latency interval. |
Enable LocalGlobal to address general data skew
The LocalGlobal optimization can filter out skewed data using local aggregation and resolve the data skew issues in global aggregation. This improves performance significantly.
The LocalGlobal optimization divides the aggregation process into two phases: local aggregation and global aggregation. The two phases are similar to the combine and reduce phases in MapReduce. In the local aggregation phase, Flink aggregates a mini-batch of locally cached data at each upstream node and outputs the accumulator value for each micro-batch. The accumulator is merged into the final result in the global aggregation phase. Finally, the global aggregation result is outputted.
Scenarios
The LocalGlobal optimization is suitable for scenarios where you want to improve performance and resolve data skew issues using common aggregate functions, such as SUM, COUNT, MAX, MIN, and AVG.
Limits
LocalGlobal is enabled by default, but it has some prerequisites:
- It can take effect only when miniBatch is enabled.
AggregateFunctionmust implement the merge contract method.
Verification
To determine whether LocalGlobal takes effect, please check whether GlobalGroupAggregate or LocalGroupAggregate nodes are in the final topology.
Enable PartialFinal to address data skew for COUNT DISTINCT
To solve the COUNT DISTINCT data skew problem, it is usually necessary to manually rewrite it as a two-layer aggregation (adding a sharding layer according to the distinct key). Currently, Ververica Cloud provides automatic sharding for COUNT DISTINCT, which is the PartialFinal optimization, so you do not need to rewrite it as a two-layer aggregation.
LocalGlobal optimization is effective in eliminating data skew for general aggregation, such as SUM, COUNT, MAX, MIN, AVG. However, the LocalGlobal optimization is less effective in improving the performance of the COUNT DISTINCT function. This is because local aggregation cannot combine distinct keys into a single record. As a result, a large amount of data is stacked up in the global aggregation phase.
Scenarios
The PartialFinal optimization is suitable for scenarios where the aggregation performance cannot meet your requirements when using the COUNT DISTINCT function.
- PartialFinal optimization can’t take effect if there are any user-defined aggregate functions (UDAFs) in Flink SQL.
- It is not recommended to enable the PartialFinal optimization if data amount is not large, as it would be a waste of resources. This is because the PartialFinal optimization would automatically break down into two layers of aggregation, introducing additional network shuffling.
Method to enable PartialFinal
PartialFinal is disabled by default. To enable this policy, you should add the following configuration in the Other Configuration section of the Parameters tab.
table.optimizer.distinct-agg.split.enabled: true
Verification
Check whether the single-layer aggregation is changed into a two-layer aggregation with a HASH shuffle in the final topology.
Aggregate With FILTER Modifier
In some cases, users may need to calculate the number of UV (unique visitors) from different dimensions, e.g., UV from Android, UV from iPhone, UV from Web, and the total UV. Many users will choose CASE WHEN to support this. Using the standard AGG WITH FILTER syntax instead of CASE WHEN is recommended to perform the multi-dimensional statistics. Flink SQL optimizer can recognize the different filter arguments on the same distinct key. Then Flink SQL can use just one shared state instance instead of multiple state instances to reduce state access and size. In some workloads, this can get significant performance improvements.
Scenarios
The performance improvement is significant for scenarios where COUNT DISTINCT results are calculated for different conditions on the same field.
Original statement
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT CASE WHEN flag IN ('android', 'iphone') THEN user_id ELSE NULL END) AS app_uv,
COUNT(DISTINCT CASE WHEN flag IN ('wap', 'other') THEN user_id ELSE NULL END) AS web_uv
FROM T
GROUP BY day
Optimized statement
SELECT
day,
COUNT(DISTINCT user_id) AS total_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('android', 'iphone')) AS app_uv,
COUNT(DISTINCT user_id) FILTER (WHERE flag IN ('wap', 'other')) AS web_uv
FROM T
GROUP BY day
Best Practice of TopN
TopN algorithms
If the input of TopN is an append-only stream, such as data streams from Kafka data sources, TopN supports only the AppendRank algorithm. If the input of TopN is an updating stream, such as data streams generated by Group Aggregation or Streaming Join, TopN supports the UpdateFastRank and RetractRank algorithms. The performance of UpdateFastRank is better than RetractRank. The algorithm name is displayed on the node name of the topology graph.
- AppendRank: Only supports append-only input streams.
- UpdateFastRank: This is the best algorithm for updating input streams.
- RetractRank: A basic algorithm for updating input streams. Poor performance, but it can be optimized to UpdateFastRank in some cases.
The following section describes how to optimize RetractRank to UpdateFastRank. If you want to use the UpdateFastRank algorithm, make sure that the following conditions are met:
- The input is an updating stream but does not contain any DELETE (D) or UPDATE_BEFORE (UB) message. You can execute the
EXPLAIN CHANGELOG_MODE <query_statement_or_insert_statement_or_statement_set>statement to check the types of messages contained in the input stream of the related node. For more information about the syntax of the EXPLAIN statement, see EXPLAIN. - The input stream contains a primary key, for example, the group keys of Aggregation.
- The update of the sorted fields is monotonic, and the monotonic direction is opposite to the sorting direction. For example,
ORDER BY COUNT/COUNT_DISTINCT/SUM(<positive_value>) DESC.
If you want to get the UpdateFastRank optimized Plan for a TopN with ORDER BY <SUM> DESC clause, you need to add a filter to make sure the actual parameter of SUM is positive, which ensures the update of SUM value is monotonic, and the monotonic direction is opposite to the sorting direction.
In the following sample code, the random_test table is an append-only stream. The aggregation result of the related group does not contain a DELETE or UPDATE_BEFORE message. Therefore, the monotonicity is retained for the related aggregation result field.
Sample code of optimizing RetractRank into UpdateFastRank:
insert
into print_test
SELECT
cate_id,
seller_id,
stat_date,
pay_ord_amt -- do not output rownum column, this can significantly reduce the amount of output data
FROM (
SELECT
*,
ROW_NUMBER () OVER (
-- Note: The PARTITION BY column must be included in the GROUP BY clause in the subquery.
-- The time field (stat_date column here) must also be included.
-- Otherwise, the data becomes disordered when the TopN state is expired.
PARTITION BY cate_id,
stat_date
ORDER
BY pay_ord_amt DESC
) as rownum -- order by the SUM result of upstream
FROM (
SELECT
cate_id,
seller_id,
stat_date,
-- Note: The result of the SUM function monotonically increases because the values in the SUM function are positive.
-- Therefore, you can use the UpdateFastRank algorithm of TopN to obtain top 100 data records.
sum (total_fee) filter (
where
total_fee >= 0
) as pay_ord_amt
FROM
random_test
WHERE
total_fee >= 0
GROUP
BY seller_id,
stat_date,
cate_id
) a
) WHERE
rownum <= 100;
TopN optimization methods
Perform no-ranking output optimization
It is recommended not to include rownum in the output of TopN and sort the TopN results when they are finally displayed in the front end. This significantly reduces the amount of data written to the external system. For more information about no-ranking optimization methods, see Top-N.
Increase the cache size of TopN
TopN provides a state cache to improve the efficiency of accessing the state data. The following formula is used to calculate the cache hit ratio of TopN:
cache_hit = cache_size*parallelism/top_n/partition_key_num
For example, Top100 is used, the cache contains 10,000 records, and the parallelism is 50. If the number of keys for the PARTITION BY is 100,000, the cache hit ratio is 5%. This ratio is calculated by using the formula: 10000 × 50/100/100,000 = 5%. The low cache hit ratio indicates that many requests access the disk state data. In this case, the performance significantly decreases.
Therefore, if the number of keys for the PARTITION BY function is large, you can increase the cache size and heap memory of TopN.
table.exec.rank.topn-cache-size: 200000
In this example, if you increase the cache size of TopN from the default value 10,000 to 200,000, the cache hit ratio may reach 100%. This cache hit ratio is calculated using the following formula: 200,000 × 50/100/100,000 = 100%.
Include a time field in the PARTITION BY clause
For example, add the “day“ field to the ranking each day. Otherwise, the TopN results become out of order due to the state data's time-to-live (TTL).
Efficient deduplication
The input data stream may contain duplicate data. Therefore, efficient deduplication is required in many cases. Ververica Cloud offers two kinds of de-duplication: Deduplicate Keep FirstRow and Deduplicate Keep LastRow.
Syntax
Flink SQL does not provide the syntax to remove duplicates. To reserve the record in the first or last row of duplicate rows under the specified primary key and discard the other duplicates, you can use the SQL ROW_NUMBER() function with an OVER clause. Deduplication is a special TopN function.
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY col1[, col2..]
ORDER BY timeAttributeCol [asc|desc]) AS rownum
FROM table_name)
WHERE rownum = 1
| Parameter | Description |
|---|---|
| ROW_NUMBER() | Assigns an unique, sequential number to each row, starting with 1. |
| PARTITION BY col1[, col2..] | Optional. Specifies the partition columns, i.e. the deduplicate key. |
| ORDER BY timeAttributeCol | Specifies the ordering column, it must be a time attribute. Currently Flink supports processing time attribute and event time attribute. Ordering by ASC means keeping the first row, ordering by DESC means keeping the last row. |
| rownum | The WHERE rownum = 1 predicate is required for Flink SQL to recognize this query as a deduplication. |
The preceding syntax shows that deduplication involves two-level queries:
- Use the
ROW_NUMBER()window function to sort data based on the specified time attribute and use rankings to mark the data.
- If the sort field is a processing-time attribute, Flink de-duplicates according to the processing time, and its result is uncertain for each run.
- If the sort field is an event-time attribute, Flink de-duplicates by the event time, and its results are determined for each run.
- Reserve only the record in the first row under the specified primary key and remove the other duplicates. You can sort records in ascending or descending order based on the time attribute.
- Deduplicate Keep FirstRow: Flink sorts records in ascending order based on the time attribute and keep the first row for every partition.
- Deduplicate Keep LastRow: Flink sorts records in descending order based on the time attribute and keep the first row for every partition.
Deduplicate Keep FirstRow
The de-duplication strategy of retaining the first row: the first occurrence of data under KEY is retained, and subsequent occurrences of data under that KEY will be discarded. Because only KEY fields, not all fields are stored in state, the performance is better than Deduplicate Keep LastRow, and the example is as follows.
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b ORDER BY proctime) as rowNum
FROM T
)
WHERE rowNum = 1
The above example is to de-duplicate the T table according to the b field and keep the first data according to the system time. In this case, proctime is a processing-time attribute in the source table T. If you de-duplicate by processing time, you can also use the PROCTIME() built-in function instead of preparing a processing-time attribute in the input table.
Deduplicate Keep LastRow
The de-duplication strategy of preserving the last row: preserving the last occurrence of data under KEY. The performance of this operation is slightly better than that of the LAST_VALUE aggregate function.
SELECT *
FROM (
SELECT *,
ROW_NUMBER() OVER (PARTITION BY b, d ORDER BY rowtime DESC) as rowNum
FROM T
)
WHERE rowNum = 1
The above example is to de-duplicate the T table according to the b and d fields and keep the last data according to the event time. In this case, rowtime is an event-time attribute in the source table T.
Efficient built-in functions
If you use built-in functions, take note of the following points:
Replacing user-defined functions (UDFs) with built-in functions
The built-in functions of Ververica Cloud are under continuous optimization, so please try to use built-in functions instead of user-defined functions if they provide the same functionality. Ververica Cloud has optimized the built-in functions as follows.
- Improves the serialization and deserialization efficiency.
- Manipulate binary data directly to avoid unnecessary serialization and deserialization.
Use single-character delimiters in the KEYVALUE function
The signature of the KEYVALUE function is KEYVALUE(content, keyValueSplit, keySplit, keyName). If keyValueSplit and KeySplit are single-character delimiters, such as colons (:) or commas (,), Ververica Cloud uses an optimized algorithm that searches for the required KeyName values in the binary data and does not split the content. The performance increases by about 30%.
Best practices of LIKE operator
- To match records that start with the specified content, use
LIKE 'xxx%'. - To match records that end with the specified content, use
LIKE '%xxx'. - To match records that contain the specified content, use
LIKE '%xxx%'. - To match records that are the same as the specified content, use
LIKE 'xxx', which is equivalent tostr = 'xxx'. - If you need to match the underscore (), remember to escape the underscore LIKE
'%seller/id%' ESCAPE '/'. The underscore () is a single-character wildcard in SQL and can match any character. If declared asLIKE '%seller_id%', it will not only matchseller_id, but alsoseller#id,sellerxidandseller1id, etc., leading to a wrong result.
Use regular functions (REGEXP) with caution
Regular expressions are very time-consuming operations, which may cause performance overhead hundreds of times higher than the addition, subtraction, multiplication, or division operation. In some extreme cases, regular expressions may go into an infinite loop and cause jobs to block. For more information, see the Regex execution is too slow thread on Stackoverflow. It is recommended to use the LIKE operator to prevent the blocking issue. Regular functions include:
- REGEXP
- REGEXP_REPLACE