Bounded Streaming Applications
Apache Flink® takes a unified approach to batch and streaming data processing. The core building block is “continuous processing of unbounded data streams”: if you can do that, you can also do offline processing of bounded data sets (batch processing use cases), because these are just streams that happen to end at some point.
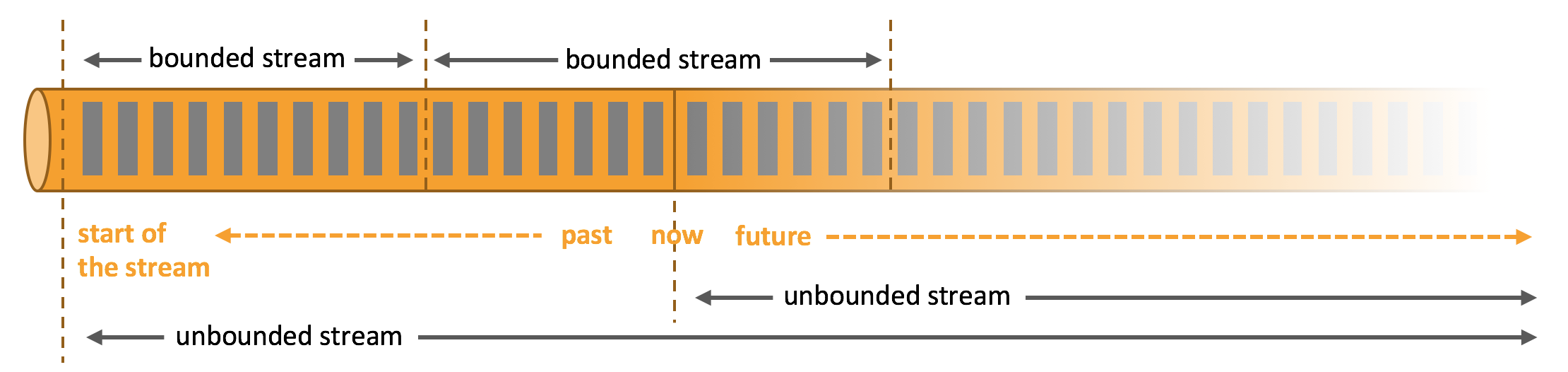
Ververica Platform understands this relationship and supports running bounded streaming applications either as finite DataStream applications or through Flink’s DataSet and Table API’s. When a batch job finishes successfully, the Deployment will change to state “FINISHED”. You can see the full job lifecycle on the Jobs page.
If you want to re-run a batch job that has already run and FINISHED, you have to manually cancel the Deployment before running again.
Apache Flink® 1.12 introduced a BATCH execution mode for the DataStream API. The Ververica Platform supports this mode on a best-effort basis.