Deployments
Deployments are the core resource abstraction within Ververica Platform to manage Apache Flink® jobs. A Deployment specifies the desired state of a Flink job and its configuration. Ververica Platform tracks and reports each Deployment's status and derives other resources from it. Whenever the Deployment specification is modified, Ververica Platform will ensure that the corresponding Flink job will eventually reflect this change.
Overview
Deployments tie together a sequence of deployed Flink Jobs, their accumulated state, an event log, policies to execute upgrades, and a template for creating Flink jobs. A Deployment will always be backed by zero or one active Flink job(s). Each Flink job is either executed in application mode or session mode.
On a high-level, each Deployment consists of three parts:
metadataAuxiliary information (e.g. name or modification timestamps) to manage the Deployment. This part is mostly user-configurable.specConfiguration and behaviour of the Deployment. This part is fully user-configurable.statusCurrent status of the Deployment. This part is read-only.
The main part of a Deployment is its spec which is described in the following sections.
Specification
The spec section is the main part of each Deployment and consists of:
- A Desired State to control the state of a Deployment.
- A Deployment Mode that determines how to deploy the Flink job.
- A Deployment Template that defines the necessary information needed to deploy a Flink job.
- A Deployment Upgrades that defines which strategy to apply when upgrading a running Flink job.
- Limits on the allowed operations Ververica Platform will perform in various scenarios.
- When creating or modifying a Deployment, optional fields will be expanded with their default values (Deployment Defaults).
Desired State
A Deployment resource has a desired state (specified in spec.state). A Deployment's desired state can be one of the following:
- RUNNING This indicates that the user would like to start a Flink job as defined in the
spec.templatesection. - CANCELED This indicates that the user would like to terminate any currently running Flink jobs.
- SUSPENDED This indicates that the user would like to gracefully terminate the currently running job and take a snapshot of its state.
When the desired state does not match the current state, Ververica Platform will try to perform a state transition to achieve the desired state.
The desired state will only be eventually achieved. The behavior of modifications happening concurrently to a state transition is undefined. Ververica Platform only guarantees that eventually the latest modification will be acted upon. Intermediate states may not be observed. This means that an ongoing state transition will not necessarily be immediately interrupted if the desired state changes while an operation is still ongoing.
Please refer to the Deployment Lifecycle page for more details.
Deployment Mode
Deployments can either be executed in application or session mode. This can be configured by providing one of the following attributes:
-
deploymentTargetNameExecute the Deployment in application mode. The name references an existing Deployment Target in the same Namespace. In this mode, the deployed Flink job will have exclusive access to the Flink cluster. -
sessionClusterNameExecute the Deployment in session mode. The name references an existing Session Cluster resource in the same Namespace. In this mode, deployed Flink jobs share resources with other Flink jobs running on the same Flink cluster.
Please refer to the Deployment Modes page for more details.
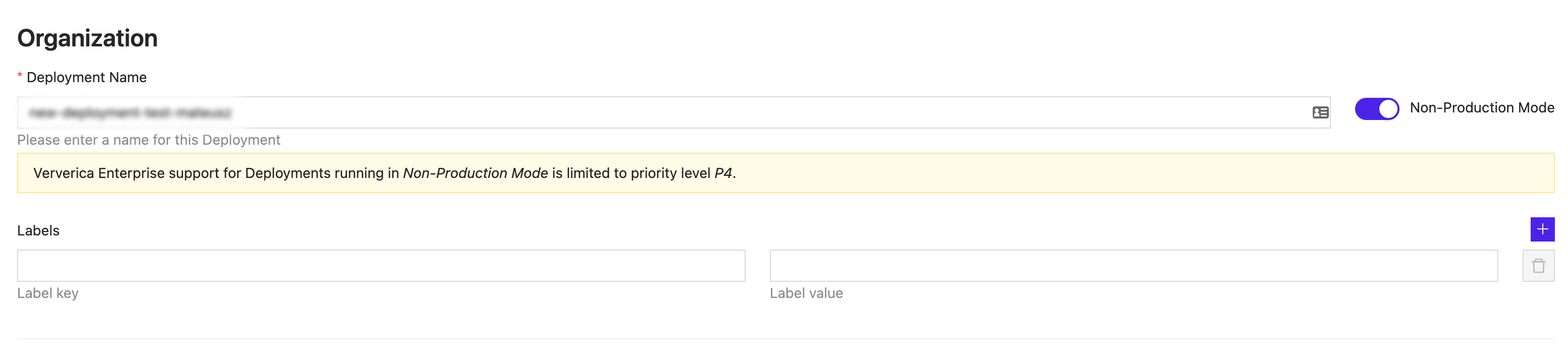
Non-production mode
A job can be deployed in non-production mode for strictly test use cases. These jobs do not count against license resources and are not supported as a production deployment.
Deployment Template
The Deployment template section specifies which Apache Flink® job job to execute and how to execute it, including its configuration.
You can think of settings in the template being directly applied to your job instances, whereas the overall Deployment specification section defines how to control these jobs over time (for instance, how to do upgrades).
Please refer to the Deployment Templates page for more details.
Deployment Upgrades
When Ververica Platform discovers that a running Flink job deviates from specified Deployment template, it will perform an upgrade of the Flink job to reconcile the situation. The behaviour of Ververica Platform is defined by an upgrade strategy (spec.upgradeStrategy) and a restore strategy (spec.restoreStrategy).
Please refer to the Deployment Upgrades page for more details.
Deployment Defaults
When a Deployment is created, default values for attributes in the spec section will be filled in as specified in the global and namespace Deployment defaults configuration. Therefore, a Deployment will be always be fully specified after it has been created.
Please refer to the Deployment Defaults page for more details.
Strategic Merge Patch for Kubernetes Pod Templates
User can add volumes, volumeMounts, and environment variables atop base settings in DeploymentDefaults. This feature enables merging new changes without sacrificing existing configurations.
Unlike Kubernetes' built-in strategic merge patch with predefined merge rules for k8s objects, this YAML directive enables users to specify which array to patch using strategic merge semantics. The directive is an element in a YAML array of two fields:
$patch: Indicates the patch method (currently only merge is supported).mergeKey: Specifies the field used to search for the target element in the target array (deployment default array) and the patch element in the patch array (deployment array) to merge.
The patch directive has several key points to consider:
-
It applies specifically to the YAML editor for deployment (JAR/PYTHON/SQL) creation.
-
It only applies to arrays within the deployment spec section.
-
It is applicable to nested arrays.
-
If
mergeKeyis missing in the directive, the patch will be appended to the target. -
If the field specified by the
mergeKeyis absent in an element of the target array, the element will be retained in the merge result. -
If the field specified by the
mergeKeyis absent in an element of the patch array, the element will be appended to the merge result.
Below is an example of each component of the merge process: Deployment Default, New Deployment, and the merged result.
Deployment Default:
spec:
maxJobCreationAttempts: 4
maxSavepointCreationAttempts: 4
restoreStrategy:
allowNonRestoredState: false
kind: LATEST_STATE
state: CANCELLED
template:
metadata:
annotations:
flink.queryable-state.enabled: 'false'
flink.security.ssl.enabled: 'false'
spec:
artifact:
flinkImageRegistry: eu.gcr.io/vvp-devel-240810
flinkImageRepository: flink
flinkImageTag: 1.18.1-stream1-scala_2.12-java8
flinkVersion: '1.18'
kind: JAR
flinkConfiguration:
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.interval: 10s
taskmanager.numberOfTaskSlots: '1'
web.cancel.enable: 'false'
kubernetes:
taskManagerPodTemplate:
spec:
containers:
- name: container-1
env:
- name: name-1-a
value: value-1-a
- name: name-1-b
value: value-1-b
volumeMounts:
- mountPath: /volume-1
name: volume-1
- mountPath: /volume-2
name: volume-2
- name: container-2
env:
- name: name-2-a
value: value-2-a
- name: name-2-b
value: value-2-b
volumeMounts:
- mountPath: /volume-1
name: volume-1
- mountPath: /volume-2
name: volume-2
volumes:
- name: volume-1
secret:
secretName: name-1
- name: volume-2
secret:
secretName: name-2
logging:
log4jLoggers:
'': INFO
loggingProfile: default
parallelism: 2
resources:
jobmanager:
cpu: 1
memory: 1G
taskmanager:
cpu: 1
memory: 2G
upgradeStrategy:
kind: STATEFUL
Deployment:
metadata:
displayName: test
spec:
deploymentTargetId: null
deploymentTargetName: test
sessionClusterName: null
template:
spec:
artifact:
jarUri: >-
https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming/1.18.0/flink-examples-streaming-1.18.0-WindowJoin.jar
kind: JAR
kubernetes:
taskManagerPodTemplate:
spec:
containers:
- name: container-1
env:
- name: name-1-a
value: value-1-a
- name: name-1-b
value: value-1-b
volumeMounts:
- mountPath: /volume-1
name: volume-1-update
- mountPath: /volume-3
name: volume-3
- $patch: merge
mergeKey: mountPath
- name: container-2
env:
- name: name-2-a
value: value-2-a
- name: name-2-b
value: value-2-b
volumeMounts:
- mountPath: /volume-1
name: volume-1-update
- mountPath: /volume-3
name: volume-3
- name: container-3
env:
- name: name-3-a
value: value-3-a
- name: name-3-b
value: value-3-b
volumeMounts:
- mountPath: /volume-1
name: volume-1
- mountPath: /volume-2
name: volume-2
- $patch: merge
mergeKey: env
volumes:
- name: volume-1
secret:
secretName: name-1-update
- name: volume-3
secret:
secretName: name-3
- $patch: merge
mergeKey: name
The merged result:
metadata:
displayName: test
spec:
deploymentTargetId: null
deploymentTargetName: test
maxJobCreationAttempts: 4
maxSavepointCreationAttempts: 4
restoreStrategy:
allowNonRestoredState: false
kind: LATEST_STATE
sessionClusterName: null
state: CANCELLED
template:
metadata:
annotations:
flink.queryable-state.enabled: 'false'
flink.security.ssl.enabled: 'false'
spec:
artifact:
flinkImageRegistry: eu.gcr.io/vvp-devel-240810
flinkImageRepository: flink
flinkImageTag: 1.18.1-stream1-scala_2.12-java8
flinkVersion: '1.18'
jarUri: >-
https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming/1.18.0/flink-examples-streaming-1.18.0-WindowJoin.jar
kind: JAR
flinkConfiguration:
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.interval: 10s
taskmanager.numberOfTaskSlots: '1'
web.cancel.enable: 'false'
kubernetes:
taskManagerPodTemplate:
spec:
containers:
- env:
- name: name-1-a
value: value-1-a
- name: name-1-b
value: value-1-b
name: container-1
volumeMounts:
- mountPath: /volume-1
name: volume-1-update
- mountPath: /volume-2
name: volume-2
- mountPath: /volume-3
name: volume-3
- env:
- name: name-2-a
value: value-2-a
- name: name-2-b
value: value-2-b
name: container-2
volumeMounts:
- mountPath: /volume-1
name: volume-1-update
- mountPath: /volume-3
name: volume-3
- env:
- name: name-3-a
value: value-3-a
- name: name-3-b
value: value-3-b
name: container-3
volumeMounts:
- mountPath: /volume-1
name: volume-1
- mountPath: /volume-2
name: volume-2
volumes:
- name: volume-1
secret:
secretName: name-1-update
- name: volume-2
secret:
secretName: name-2
- name: volume-3
secret:
secretName: name-3
logging:
log4jLoggers:
'': INFO
loggingProfile: default
parallelism: 2
resources:
jobmanager:
cpu: 1
memory: 1G
taskmanager:
cpu: 1
memory: 2G
upgradeStrategy:
kind: STATEFUL
Limits
During state transitions of a Deployment, Ververica Platform creates Job resource and potentially triggers a Savepoint.
These operations might fail due to transient reasons, like a network issue, or misconfiguration. For these cases you can limit the number of attempts that Ververica Platform tries to create a Job or Savepoint before transitioning to a FAILED state:
| Key | Description | Default |
|---|---|---|
maxSavepointCreationAttempts | Maximum attempted Savepoints before failing. | 4 |
maxJobCreationAttempts | Maximum Job creation attempts before failing. | 4 |
The behavior on failed job creation attemps can be customized by setting the jobFailureExpirationTime duration parameter. Any attempts older than the specified value will be disregarded. If set to 0 or not specified, old attempts will be considered indefinitely.
The input string needs to conform with: “{amount}{time unit}”, e.g. “123ms”, “321 s”. Supported time units are:
| Unit | shorthand |
|---|---|
| DAYS | d, day |
| HOURS | h, hour |
| MINUTES | min, minute |
| SECONDS | s, sec, second |
| MILLISECONDS | ms, milli, millisecond |
| MICROSECONDS | µs, micro, microsecond |
| NANOSECONDS | ns, nano, nanosecond |
Full Example
The following snippets are a complete example of a Deployment in application mode and session mode, including all optional keys and a Deployment Template.
- Application Mode
- Session mode
kind: Deployment
apiVersion: v1
metadata:
name: top-speed-windowing-example
displayName: TopSpeedWindowing Example
labels:
env: testing
spec:
state: RUNNING
deploymentTargetName: default
restoreStrategy:
kind: LATEST_STATE
upgradeStrategy:
kind: STATEFUL
maxSavepointCreationAttempts: 4
maxJobCreationAttempts: 4
template:
metadata:
annotations:
flink.queryable-state.enabled: 'false'
flink.security.ssl.enabled: 'false'
spec:
artifact:
kind: jar
jarUri: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.12.7/flink-examples-streaming_2.12-1.12.7-TopSpeedWindowing.jar
additionalDependencies:
- s3://mybucket/some_additional_library.jar
- s3://mybucket/some_additional_resources
mainArgs: --windowSize 10 --windowUnit minutes
entryClass: org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
flinkVersion: 1.12
flinkImageRegistry: registry.ververica.com/v2.10
flinkImageRepository: flink
flinkImageTag: 1.12.7-stream2-scala_2.12
flinkConfiguration:
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.interval: 10s
high-availability: vvp-kubernetes
state.backend: filesystem
parallelism: 2
numberOfTaskManagers: 2
resources:
jobManager:
cpu: 1
memory: 1g
taskManager:
cpu: 1.0
memory: 2g
logging:
loggingProfile: default
log4jLoggers:
"": INFO
org.apache.flink.streaming.examples: DEBUG
kubernetes:
pods:
envVars:
- name: KEY
value: VALUE
kind: Deployment
apiVersion: v1
metadata:
name: top-speed-windowing-example
displayName: TopSpeedWindowing Example
labels:
env: testing
spec:
state: RUNNING
sessionClusterName: default
restoreStrategy:
kind: LATEST_STATE
upgradeStrategy:
kind: STATEFUL
maxSavepointCreationAttempts: 4
maxJobCreationAttempts: 4
template:
spec:
artifact:
kind: jar
jarUri: https://repo1.maven.org/maven2/org/apache/flink/flink-examples-streaming_2.12/1.12.7/flink-examples-streaming_2.12-1.12.7-TopSpeedWindowing.jar
mainArgs: --windowSize 10 --windowUnit minutes
entryClass: org.apache.flink.streaming.examples.windowing.TopSpeedWindowing
flinkConfiguration:
execution.checkpointing.externalized-checkpoint-retention: RETAIN_ON_CANCELLATION
execution.checkpointing.interval: 10s
high-availability: vvp-kubernetes
state.backend: filesystem
parallelism: 2