Flink Configuration
Flink configuration options provided on the SessionCluster resource are applied on the Flink cluster-level. On this page, we describe how the Flink configuration is applied to your session cluster and highlight important configuration options.
Overview
The Flink configuration is specified as part of the SessionCluster spec.
kind: SessionCluster
spec:
flinkConfiguration:
key: value
Please consult the official Flink documentation for a listing of available configuration options.
Environment Variables
You can reference environment variables inside flinkConfiguration through shell format strings:
kind: SessionCluster
spec:
flinkConfiguration:
s3.access-key: ${S3_ACCESS_KEY}
This allows you to store sensitive information such as passwords, keys and tokens as Kubernetes secrets and reference them by setting up an environment variable via Kubernetes Pod Templates or a custom Flink Docker image.
File Systems
The default Flink Docker images provided by Ververica Platform include FileSystem implementations for popular blob storage providers.
| Blob Storage Provider | Scheme | FileSystem Implementation |
|---|---|---|
| File System | file | LocalFileSystem |
| AWS S3 | s3, s3p | PrestoS3FileSystem |
| AWS S3 | s3a | S3AFileSystem |
| Microsoft ABS | wasbs | NativeAzureFileSystem |
| Apache Hadoop® HDFS | hdfs | HadoopFileSystem |
| Microsoft ABS Workload Identity | wiaz | Ververica custom plugin implementation |
If you use Universal Blob Storage, all relevant Flink options, including credentials, will be configured on the Flink cluster-level. Please consult the official Flink documentation for details about manual configuration of file systems.
Note that additional file system implementations have to be loaded as Flink plugins which requires a custom Flink Docker image.
High-Availability (Jobmanager Failover)
Flink requires an external service for high-availability in order to be able to recover the internal state of the Flink Jobmanager process (including metadata about checkpoints) on failures.
By default, Flink Jobmanager failover is not enabled. For production installations it is highly recommended to configure Flink with such a service. Please refer to the Flink configuration for details on how to configure high-availability services manually.
Kubernetes
Ververica Platform supports two options for Flink high-availability services on Kubernetes that do not have any additional dependencies, Flink Kubernetes and Ververica Platform Kubernetes. See Kubernetes High-Availability Service for discussion.
Flink Kubernetes
The high-availability service is enabled via the following configuration:
kind: SessionCluster
spec:
flinkConfiguration:
high-availability: kubernetes
If Universal Blob Storage
is not configured, you have to additionally provide the
high-availability.storageDir configuration.
Access Control
When enabled, your Flink application will require access to the API of your Kubernetes cluster.
ConfigMap resources will be automatically created for high-availability metadata and leader election of Jobmanager.
For Flink Kubernetes:
session-$sessionClusterId-$jobIdWithoutDash-config-map: high availability metadatasession-$sessionClusterId-cluster-config-map: leader election
Flink Kubernetes requires permissions to get/create/edit/delete ConfigMaps in the namespace.
The permissions are applied via Kubernetes Role Based Access Control
(RBAC) resources that are created per Flink cluster. The created roles
are bound to a custom ServiceAccount that is assigned to each
Flink pod of the cluster.
Limitations
- High-availability service accesses your Kubernetes cluster, see Kubernetes High-Availability Service for details.
- If your default service account in target Kubernetes namespace has
additional configuration (such as image pull secrets) or other
access control restrictions, this will not be reflected in the
created
ServiceAccountresources. Therefore, you have to manually provide any additional configuration on the Deployment level, see Kubernetes Resources. - The High Availability Service requires Kubernetes RBAC.
Deprecated Ververica Platform Kubernetes
Ververica Platform Kubernetes has some additional limitations:
- The Jobmanager ConfigMap
sessioncluster-$sessionClusterId-flink-ha-jobmanageris used to store failover metadata. ConfigMaps and other API resources in Kubernetes have a maximum resource size that limits how much metadata can be stored for recovery. The metadata size grows with the number of Flink jobs running on the session cluster. The number of jobs that can be executed concurrently per cluster varies depending on your configuration (e.g. how many checkpoints are retained, storage location, etc.), but in a typical installation you can expect to be able to run 100+ jobs per session cluster without running into the size limit. - The latest state restore strategy requires the Kubernetes high-availability service. Checkpoint metadata is cleaned up periodically in order to avoid hitting the maximum resource size limit mentioned above. If Ververica Platform cannot create a Savepoint resource for each retained checkpoint before the metadata is cleaned up, retained checkpoints might be missed for Deployments running in session mode.
- By default, checkpoint metadata is cleaned up 15 minutes after the
job has been unregistered. If you experience unexpected delays
during Deployment termination, you can increase this delay via the
high-availability.vvp-kubernetes.checkpoint-store.gc.cleanup-after-minutes: 15option. This limitation does not apply to Deployments running in application mode.
SSL/TLS Setup
Ververica Platform can be configured to auto-provision SSL/TLS for Flink via the following annotation:
kind: SessionCluster
metadata:
annotations:
flink.security.ssl.enabled: true
This annotation enables SSL with mutual authentication between Flink's internal network communication and Flink's REST API and web user interface. Requests to Flink's REST API will now flow via Ververica Platform's Flink proxy which has access to the trusted client certificate. Additionally, SSL is enabled in communication between Ververica Platform Result Fetcher service and Flink's REST API.
Currently for Session Cluster SSL, the Flink blob.service.ssl (part of Flink internal communication, responsible for securing transport of BLOBs from Jobmanager to Taskmanager) is disabled by default.
Currently, Ververica Platform does not support SSL in SQL editor preview. For that use case, please user Session Clusters with SSL disabled.
By default, SSL is disabled. Enabling this option will set the required Flink SSL configuration parameters, overwriting any existing configuration.
SSL Provider
Currently, Flink supports two different SSL providers:
security.ssl.provider: OPENSSL: OpenSSL-based SSL engine using system librariessecurity.ssl.provider: JDK: pure Java-based SSL engine
Note that not all SSL algorithms set via security.ssl.algorithms are supported by OpenSSL.
The provider can be set back to the native JDK implementation, security.ssl.provider:JDK to allow other algorithms.
Implementation
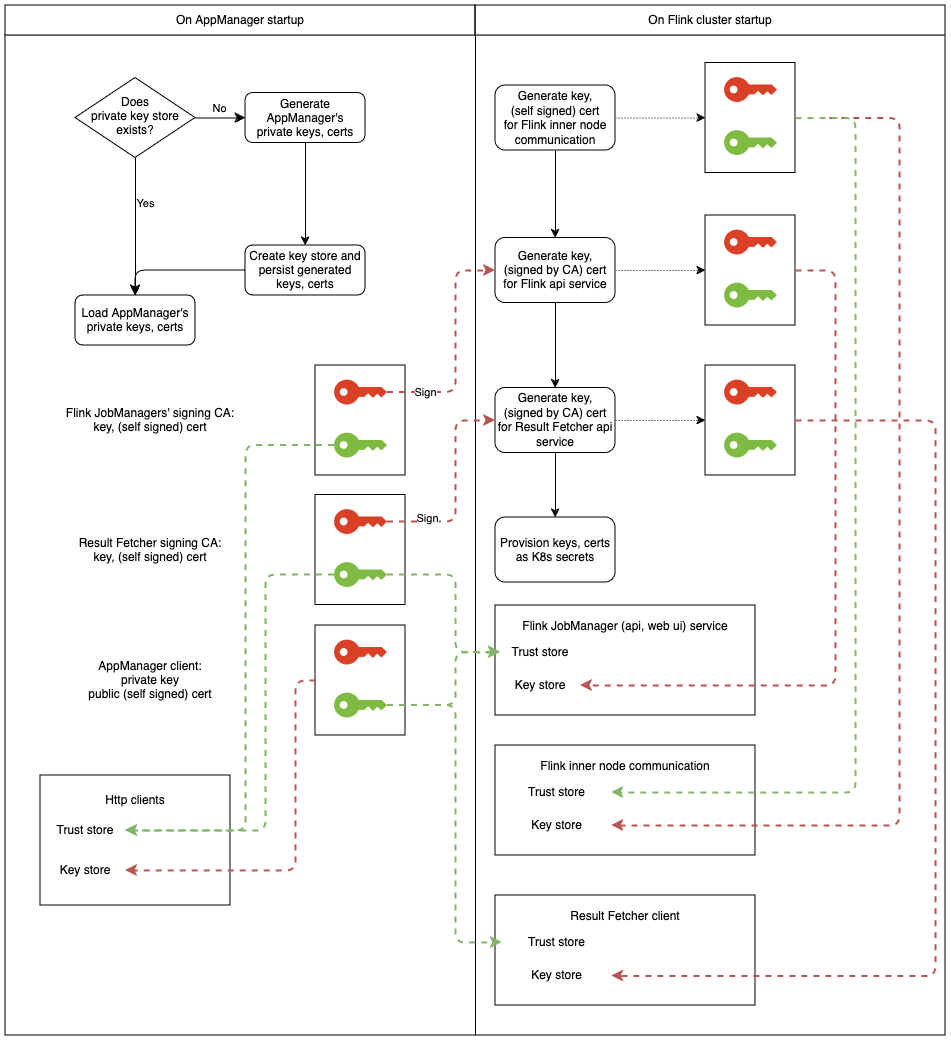
To provision Flink clusters with key stores and trust stores, Ververica Platform generates each of the following once:
- a self-signed certificate where the public key is shared with Flink jobmanager instances and Result Fetcher service.
- a self-signed signing certificate (CA) for signing SSL certificates for Flink jobmanager and Result Fetcher All certificates with private keys are stored in a key store under the Ververica Platform persisted directory.
Before starting a Session Cluster with the configuration enabled, Ververica Platform will generate:
- a self-signed certificate, used to enable secure Flink internal connectivity
- a certificate signed by the signing certificate to enable https on Flink jobmanager's REST API and web UI
- a certificate signed by the signing certificate to enable https on Result Fetcher REST client All certificates with private keys are saved in a Kubernetes secret, which later is mounted to each Deployment's Flink nodes.
The implementation can be interpreted visually in the following diagram:
SSL in SQL editor preview
As of Ververica Platform version 2.13, the SSL in SQL editor preview is disabled. To replace this functionality while using SSL in communication, follow the steps below:
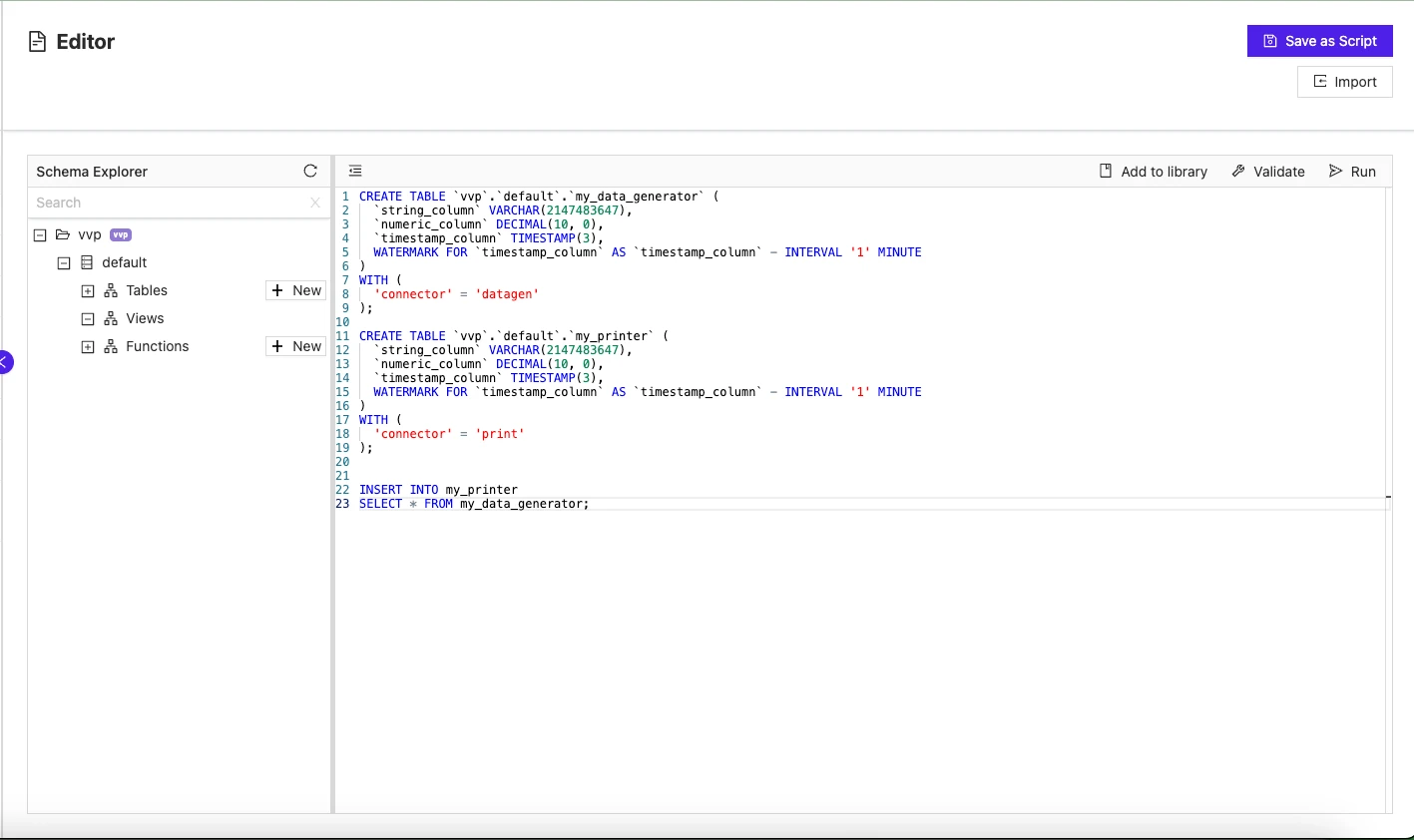
- Prepare the desired SQL
SELECTstatement to run in the SQL editor preview. - Create a sink table with matching columns and with the connector type
print. - Create an SQL Deployment from the
SELECTstatement output inserted into the sink table. - Enable SSL in the created SQL Deployment.
- Start the SQL Deployment and verify its output in the Flink Taskmanager logs.
Queryable State
Ververica Platform supports Flink Queryable State.
kind: SessionCluster
metadata:
annotations:
flink.queryable-state.enabled: "true"
This enables Queryable State and configures an additional Kubernetes service that allows access to the Queryable State server launched on each Taskmanager.
This will allow you to query Flink state with a QueryableStateClient from the Kubernetes cluster using
sessioncluster-${sessionClusterId}-taskmanager:9069 as an address, where sessionClusterId corresponds to the ID of your session cluster.