Autopilot
This feature is only available in Ververica Platform Stream Edition and above.
Autopilot in Ververica Platform provides automatic configuration of Apache Flink® Deployments in order to reduce operational complexity and use computing resources efficiently.
Concepts
Autopilot is configured via Autopilot Policies. There is a policy for each Deployment. The policy configures the corresponding Autopilot Agent for the Deployment. The agent is responsible for monitoring the Deployment and providing configuration recommendations.
In the web frontend, the Autopilot tab on the Deployment details page exposes all available options for configuring a policy, and displays the agent's status information and recommendations. Our OpenAPI specification lists all available Autopilot endpoints with example requests and responses.
Mode
Each policy is in one of the following modes: DISABLED (default), MONITORING, or ACTIVE. The mode specifies how the autopilot agent is executed and whether recommendations are actively applied.
| Mode | Status/recommendation updated? | Recommendation applied automatically? |
|---|---|---|
| DISABLED | No | No |
| MONITORING | Yes | No |
| ACTIVE | Yes | Yes |
In addition to the mode, there are more fine-grained configuration options available for Autoscaling.
DISABLED (default)
Disables the autopilot agent. No status and no recommendation will be computed. This is the default for every policy.
MONITORING
The autopilot agent passively monitors the corresponding Deployment. The status and recommendation endpoints will be continuously updated, but recommendations will not be applied automatically.
You can use this mode as a dry-run before activating the autopilot. When you do want to apply a recommendation, you can use the web frontend to apply it manually or use the Deployment PATCH API with the recommended JSON patch.
ACTIVE
The autopilot actively monitors the corresponding Deployment and applies recommendations automatically. The status and recommendation responses will be continuously updated.
You can track applied recommendations by listing Deployment Events in the web frontend or querying the events API.
Status
When a policy is in mode MONITORING or ACTIVE, the corresponding autopilot agent will report its runtime status.
The status report includes OK or ERROR as a high-level summary. Please check the Autoscaling section for details on the autoscaler specific status report.
Recommendation
Each autopilot agent can provide a recommendation to update the configuration of the Deployment it is monitoring. The recommendation is provided as a JSON Deployment patch that specifies how the agent would update the corresponding Deployment. Depending on the policy configuration, the autopilot can directly apply its recommendation to the Deployment (ACTIVE mode) or only report it for manual application (MONITORING mode).
When a recommendation is automatically applied, you will additionally see Deployment Events being logged.
Autoscaling
When Autopilot is enabled for a Deployment, the autoscaler will monitor the Deployment and provide recommendations to scale the Deployment in or out by adjusting the Deployment's parallelism (horizontal scaling). When an autoscaling recommendation is applied, the Deployment will be upgraded using the configured Deployment upgrade strategy.
Recommendations to scale out are driven by estimates of the required input rate for each source and recommendations to scale in by the utilization of the pipeline's bottleneck. The goal of the autoscaler is to find a parallelism that results in a backpressure-free data flow while minimizing overprovisioning.
Requirements
In order to make scaling recommendations the autoscaler requires Flink jobs to fulfill the following requirements:
- Apache Flink® 1.11: The minimum required Flink version is 1.11.0 or newer.
- Apache Kafka® sources: All sources of the Flink job need to use the Universal Apache Kafka connector.
- Application Mode: Autoscaling is only supported for Deployments in application mode.
If any of the above requirements are not met, the autoscaler will report an error and no recommendations will be provided.
Configuration
The following options are available for the autoscaler. You can configure these via the web frontend or the API.
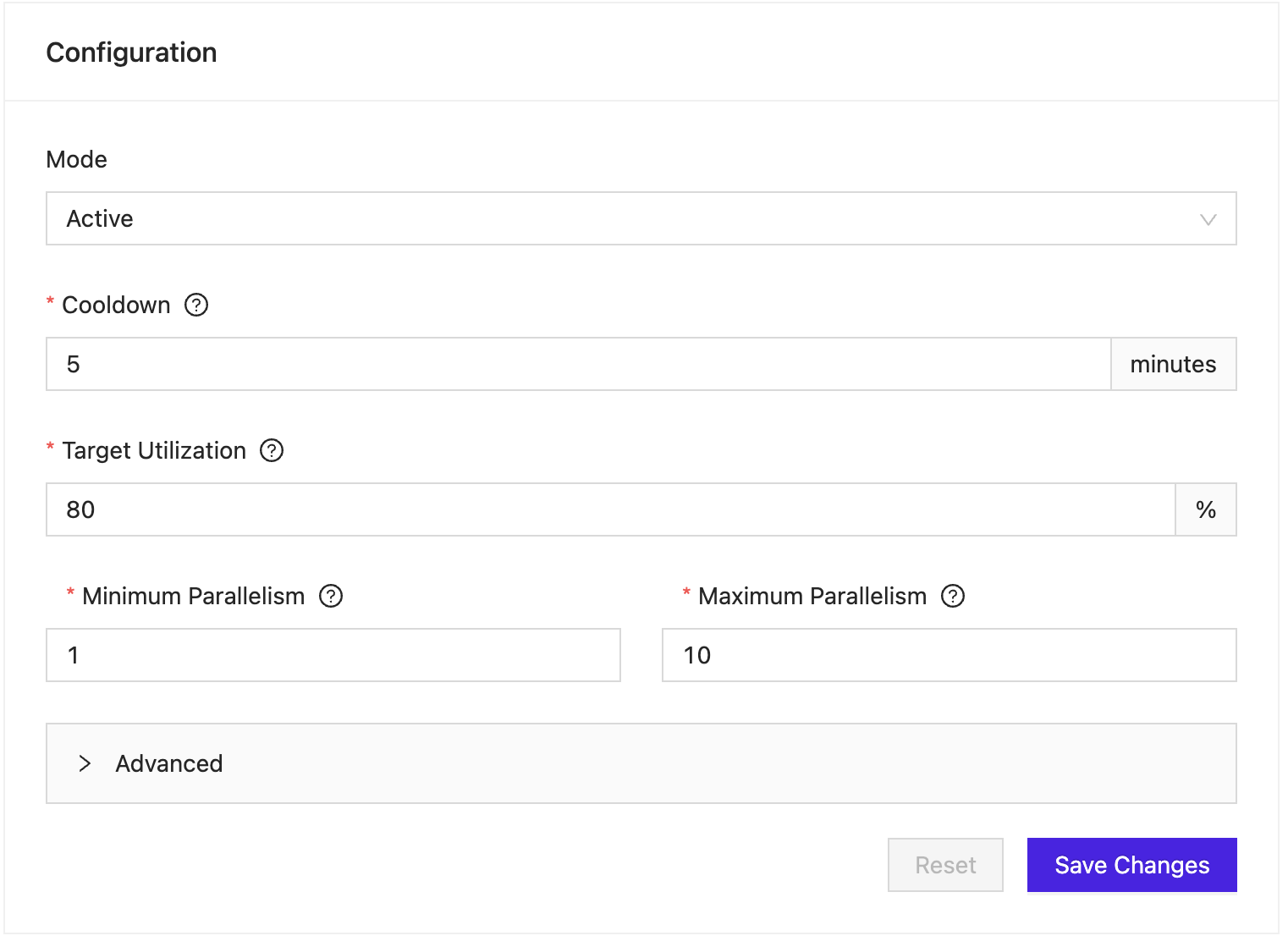
Cooldown (default: 5 minutes)
The minimum amount of time (in minutes) that needs to pass between the automatic application of two scaling recommendations. When a scaling recommendation is applied, the corresponding Deployment will be redeployed. This results in down time for your application. If you set the cooldown to a too low number, your application might not have enough time to catch up with its input after rescaling. Note that the time to restore the application state from a snapshot is part of the redeployment time and needs to be accounted for in the cooldown configuration.
Minimum parallelism (default: 1)
The minimum parallelism of a Deployment. The autoscaler will not recommend a parallelism lower than this number. This setting can help to ensure that your Deployment will not be underprovisioned.
Maximum parallelism (required)
The maximum parallelism of a Deployment. The autoscaler will not recommend a parallelism greater than this number. This setting can help to ensure that your Deployment will not be overprovisioned or consume too many compute resources.
When you are configuring a number larger than 128, you have to adjust your job maximum parallelism configuration accordingly. This is required when you enable Autopilot.
Target utilization (default: 80%)
The target utilization determines the desired utilization of the Flink job, controlling how much spare capacity the job should have after scaling. The configured value is a number in the range between 1 and 100. In general, it is not recommended to set this value to 100 as it does not leave any spare capacity to catch up after scaling.
When making scaling recommendations the target utilization determines the expected utilization after scaling and catch-up.
You can configure Autopilot to log the current Flink metrics including job, task and task manager. Autopilot will also log details of new parallelism recommendations for the running Deployment. See Configuring Logging below for details, including how to view the log output.
When logging is configured:
- Autopilot periodically pulls and logs the current values of Flink metrics.
- When you propose or apply a new parallelism configuration, Autopilot will log the Flink metrics used as input to its parallelism calculations, and will report the resulting recommended parallelism.
You can use the log output to monitor the current Deployment parallelism state, and as feedback to help you understand how the configuration options are applied in practice to determine a parallelism value.
Advanced Configuration
The following options are available for the autoscaler. You can configure these via the web frontend or the API.
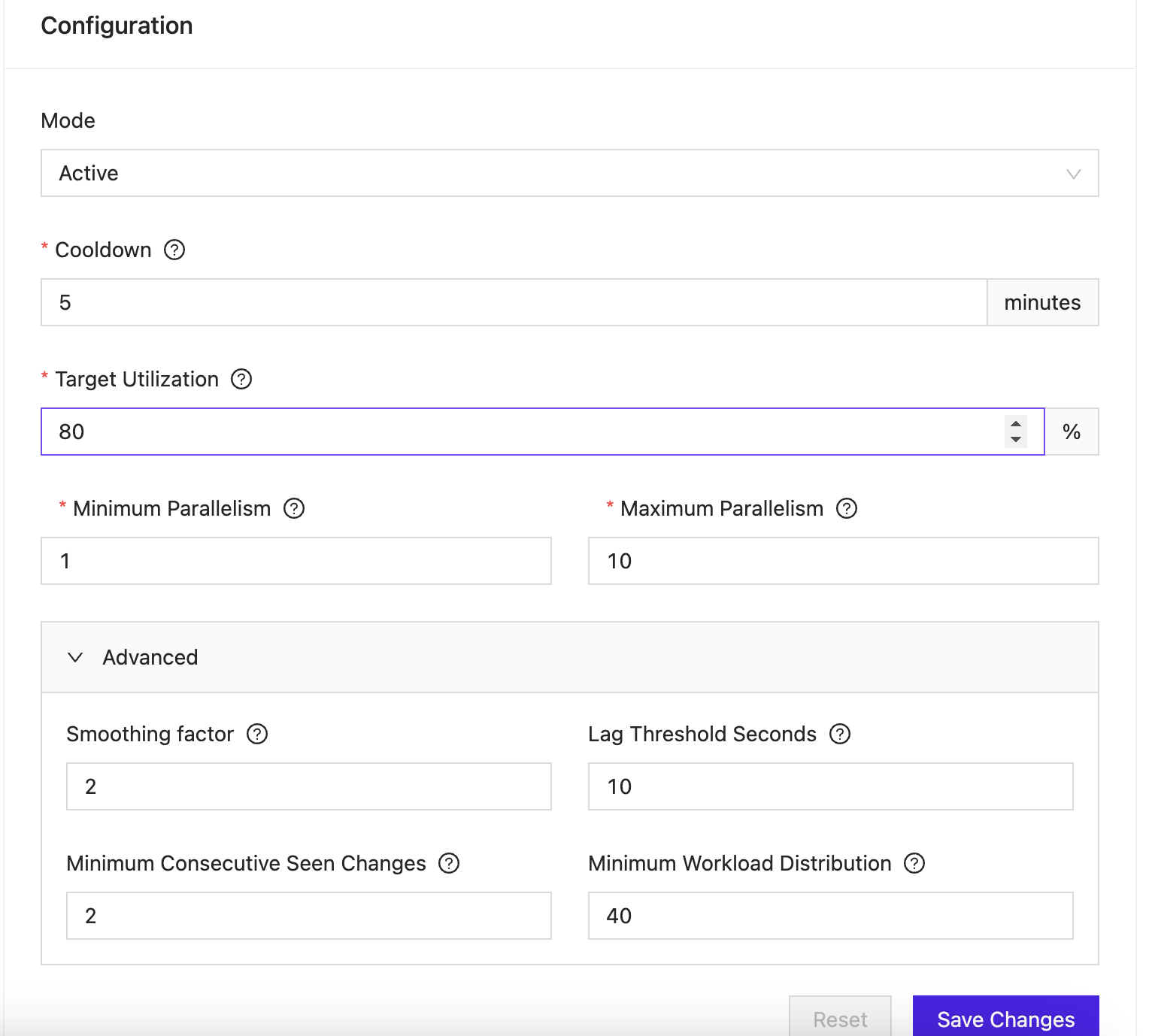
Smoothing Factor
This setting determines the number of time windows considered for calculating various task metrics, such as:
- The number of Kafka partitions assigned to a task.
- The duration of task idleness (when there is no data to process).
- The number of records a task transmits per second.
Minimum Consecutive Seen Changes
Specifies the required number of consecutive, similar recommendations (either increase or decrease) before the VVP Autopilot implements a change. A new, contrasting recommendation resets this count. Increasing this parameter ensures that the Autopilot algorithm responds only to more sustained trends, although it may delay adjustments in task parallelism.
Lag Threshold Seconds
The minimum time, in seconds, needed for a task to catch up with its lag, given its current throughput, before Autopilot's recommendations are enacted.
Minimum Workload Distribution
This parameter represents the minimum percentage difference between the lightest and heaviest workloads across tasks required by VVP Autopilot to issue a recommendation. Raising this value means the Autopilot algorithm will wait for a more balanced workload distribution across tasks before making adjustments.
Assumptions
When monitoring a Deployment the autoscaler makes the following assumptions about the Flink job. Please ensure that these assumptions apply when using Autopilot. Otherwise, the recommended scaling decisions might be ineffective.
Streaming job
The autoscaler is designed to handle streaming workloads only.
Job is horizontally scalable
The autoscaler assumes that the Flink job being monitored is horizontally scalable. Two typical cases when this assumption is violated are the following:
- High data skew: With high data skew single tasks stay overloaded after scaling out, resulting in the scaling decision to have only a minimal or no effect on the load distribution. This applies to both source tasks as well as intermediate tasks.
- Too few Apache Kafka® partitions: With too few Kafka partitions, some source tasks will be idle after the job parallelism exceeds the number of Kafka partitions. If the data is distributed to down stream tasks (for instance via a
keyByoperation), having less Kafka partitions than parallelism is typically acceptable.
Bottleneck not in the source tasks
If the bottleneck of your pipeline is in the source tasks (e.g. a task that is chained to the source), scaling recommendations will be limited:
-
Scaling in will not work, because the idleness metric used for scale in decisions is not meaningful for source tasks yet. This limitation is planned to be resolved by the Flink community in the upcoming Flink 1.12 release.
-
Scaling out will only help until your source task parallelism reaches the number of Apache Kafka® partitions. In this case, it can be desirable to break up the task chain manually in order to distribute the data to down stream tasks.
No manual parallelism overrides
Your Flink job may not configure any parallelism in code by calling setParallelism(int) on a task or the environment. Otherwise the parallelism configured by Autopilot will be ignored by your job.
No manual slot sharing
Flink jobs that manually manage slot sharing
groups
are not supported. The autoscaler assumes default slot sharing, e.g. a
job with parallelism n requires n task slots.
Configuring Logging
When logging is configured, Autopilot periodically pulls and logs the current values of the Flink metrics, enabling you to monitor the current Deployment parallelism state. These lines are marked as DEGUB in the log output.
When you change the Autopilot configuration, Autopilot logs the Flink metrics used as input to its parallelism calculations, and reports the calculated target parallelism. These lines are marked as INFO in the log output.
To set logging on, add the following to the main YAML configuration file used to install the platform:
topLevelConfig:
logging:
level:
com.ververica.autopilot.AutopilotAgent: debug
Then use the helm upgrade --install command to upgrade the installation.
Logging must be configured from the main installation configuration. This configuration cannot be added dynamically.
The log output is available from the GatewayApplication container inside the Kubernetes pod.
To view it, execute these commands:
kubectl get pods // search for vvp pod installation
kubectl log vvp-pod-name -c gateway -f // show logs from gateway container
The following example output shows typical Autopilot periodic DEGUB lines for an agent thread:
2023-06-26 10:40:03.164 DEBUG 1 --- [-agent-thread-2] com.ververica.autopilot.AutopilotAgent : Pulling metrics for deployment: autopilot-test-producer with jobId: Optional[a20eed058b2e4544b3df4497ef0d8d45]
2023-06-26 10:40:03.165 DEBUG 1 --- [-agent-thread-2] com.ververica.autopilot.AutopilotAgent : Metrics values: {recordsLagMax={}, sourceRecordsOutPerSecond={cbc357ccb763df2852fee8c4fc7d55f2={0=MinMaxMean(min=5000.0, max=5000.0, mean=5000.0, count=2), 1=MinMaxMean(min=4991.833333333333, max=5010.6, mean=5001.216666666667, count=2)}}, assignedPartitions={}, sourceIdleness={c27dcf7b54ef6bfd6cff02ca8870b681={0=MinMaxMean(min=961.0, max=963.0, mean=962.0, count=2), 1=MinMaxMean(min=938.0, max=983.0, mean=960.5, count=2)}}}
The following example output shows typical Autopilot INFO lines for a proposed new parallelism configuration:
2023-06-26 10:56:23.432 INFO 1 --- [-agent-thread-0] com.ververica.autopilot.AutopilotAgent : Suggested parallelism change from 2 to 4 for deployment autopilot-test-consumer
2023-06-26 10:56:23.433 INFO 1 --- [-agent-thread-0] com.ververica.autopilot.AutopilotAgent : Updated metrics after parallelism suggestion: {sourceRecordsOutPerSecond={cbc357ccb763df2852fee8c4fc7d55f2={0=MinMaxMean(min=0.0, max=0.0, mean=0.0, count=2), 1=MinMaxMean(min=0.0, max=0.0, mean=0.0, count=2), 2=MinMaxMean(min=9904.233333333334, max=10276.55, mean=10090.391666666666, count=2), 3=MinMaxMean(min=0.0, max=0.0, mean=0.0, count=2)}}, assignedPartitions={cbc357ccb763df2852fee8c4fc7d55f2={2=MinMaxMean(min=1.0, max=1.0, mean=1.0, count=2)}}, sourceIdleness={90bea66de1c231edf33913ecd54406c1={0=MinMaxMean(min=992.0, max=1000.0, mean=996.0, count=2), 1=MinMaxMean(min=995.0, max=1000.0, mean=997.5, count=2), 2=MinMaxMean(min=782.0, max=836.0, mean=809.0, count=2), 3=MinMaxMean(min=662.0, max=995.0, mean=828.5, count=2)}}, recordsLagMax={cbc357ccb763df2852fee8c4fc7d55f2={2=Optional[PastAndCurrentValue(pastValue=MinMaxMean(min=45543.0, max=629109.0, mean=202913.0, count=4), currentValue=MinMaxMean(min=40432.0, max=45543.0, mean=41971.75, count=4))]}}}
The logged Flink metrics provide a permanent detailed record of the summary metrics shown by the Web frontend:
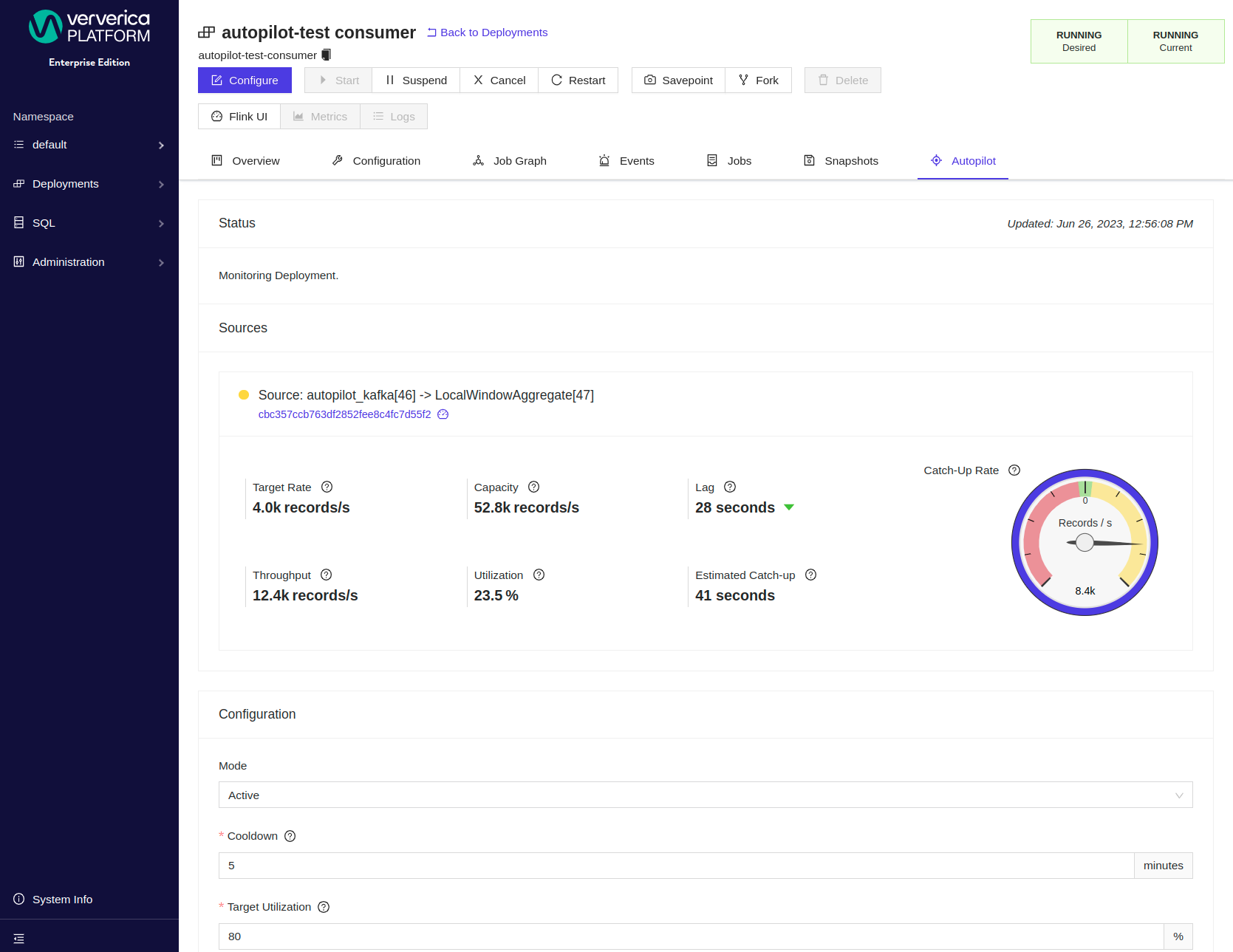
Status & Recommendations
When you open the Autopilot tab on the Deployment details page, you will find the latest recommendation and status information.
Status
Task Name
The name of the source task as configured in the Flink job.
Vertex ID
ID of the task as reported by Flink. Note that a single task may contain multiple chained operators.
Throughput
The number of records per second that the source is processing.
Capacity
The estimated capacity in records per second that the source can process.
Target Throughput
The estimated target number of records per second that the source should process.
Estimated Lag (Seconds)
The estimated time in seconds that the source is behind the latest record in the Apache Kafka® topic.
- If this number is getting smaller over time, your source is catching up with its input.
- If this number stays roughly the same, the source is keeping up with its input.
- If this number is getter larger over time, your source cannot catch up with its input.
Estimated Catch-Up (Seconds) The estimated time in seconds the source needs to catch up with the latest record in the Apache Kafka® topic.
Recommendation
The autoscaler updates the recommendation endpoint with a JSON patch that specifies the recommended parallelism for the Deployment.
{
"spec": {
"parallelism": number
"numberOfTaskManagers": number
}
}
The number of task managers configuration is only adjusted when your original Deployment had it set. The task slot configuration is never adjusted automatically.
You can use this patch with the Deployment API or apply it via the web frontend.
Future Work
API version
The Autopilot API is currently marked as v1alpha1. As such, the API might have breaking changes in the future.
Scaling requires redeployment When a scaling recommendation is applied, the Flink cluster will be torn down completely and redeployed with the updated parallelism. This results in down time that can lead to additional record lag. The cooldown configuration should account for this down time and allow a rescaled job enough time to catch up with its input. In future versions we plan to reduce this down time for pure rescaling operations.
Rollback of failed upgrades When a Deployment upgrade fails (for instance due to exhausted resource quota after scaling up), the autoscaler does not roll back the Deployment to its earlier state, requiring manual intervention. In future versions we plan to provide configuration options to roll back changes in case of failures.