PyFlink development with Apache Flink®
PyFlink is a Python API for Apache Flink®. It provides Python bindings for a subset of the Flink API, so you can write Python code that uses Flink functions and that can be executed on a Flink cluster. Your Python code executes as a PyFlink job, and runs just like other Flink jobs.
Prerequisites
On Ververica Platform 2.10, follow the Getting Started guide to deploy a platform instance and set up the example playground. This will configure a local working environment that includes Python and PyFlink where you can test the examples in this guide.
If you are running an older version of Ververica Platform (2.8 or 2.9) you may need to build a custom Docker image to include Python and PyFlink, depending on your platform/Flink combination. To do so, follow the steps in Building a Platform Image, below.
If you are just getting started with Ververica Platform and its core concepts, then this short video is a good overview of basic deployment and job management.
Concepts
Using PyFlink, you can write Python code that interoperates with core Flink functionality.
Jobs
Jobs are the high level executable resource abstraction in Flink. At a lower level, pipelines execute sequences of highly parallelised tasks, for example database queries, map functions, reduce functions and so on, across source data streams. Jobs bundle tasks with input streams and manage task execution and statefulness, via checkpoints and snapshots.
PyFlink jobs are Flink jobs you create from Python code using PyFlink.
PyFlink UDFs
UDFs are User Defined Functions. Most SQL queries you write use functions to perform logic inside the query, and Flink includes a rich set of built-in functions. When you need to extend these to implement custom logic you define and register UDFs.
Using PyFlink, you can write your custom functions in Python.
Table API
The Flink Table API provides a unified SQL API for Java applications that abstracts the differences between different kinds of data source, for example stream or batch sources, and creates a common semantics.
PyFlink allows you to call Python UDFs from Java Table API Flink applications.
Getting Started
In this tutorial we take you through the steps to:
- Write and register a custom Python UDF.
- Configure and run the custom UDF in a PyFlink Job from Ververica Platform.
- Call your Python UDF from a Java Table API application.
In Ververica Platform v2.10 PyFlink and Python are already included. For earlier versions of the platform, or for any version if you are using a Flink version earlier than 1.15.3 (e.g. Flink 1.13/1.14 with platform versions 2.8/2.9), then follow the steps to build and push a custom platform image. With PyFlink and Python included in your image you can follow this tutorial.
Create a Python UDF
In this example we will:
- Write a custom Python UDF.
- Use the UDF in a Python program.
User-defined functions (UDFs) allow you to add your own custom logic to a Flink application. PyFlink provides APIs and bindings that allow you to write UDFs in Python and access Python libraries to write queries and process data.
Here we write a simple Python function that takes a string as input and returns it in upper case form, and declare it as a UDF:
from pyflink.table.udf import udf
from pyflink.table import DataTypes
@udf(result_type=DataTypes.STRING())
def py_upper( str ):
"This capitalizes the whole string"
return str.upper()
The annotation @udf(result_type=DataTypes.STRING()) is the glue that makes this function available as a Python UDF.
Annotation is the simplest way to define a Python UDF, but you can also use the py_upper = udf(...) syntax, for example if you want to define a lambda function on the fly. See the official Flink documentation for details.
Let's see how to use this UDF in an example Python program.
The example program pyflink_table_example.py, available on GitHub defines some simple table data and a SQL query over it. It's a simple but complete Python program that uses the sys and logging standard Python libraries , a PyFlink library pyflink.table, and that imports and invokes our Python UDF to change the results of a table query to upper case (we just show a fragment of the code here):
t_env.create_temporary_function("PY_UPPER", my_udfs.py_upper)
...
t_env.sql_query("SELECT id, PY_UPPER(city) city FROM %s" % my_table) \
.execute() \
.print()
This is a simple example, but you can use the full power of Python and Python libraries to create complex functions and call them from a complete analytic or data processing application written in Python. The Python code interoperates with Flink.
Run a Python UDF in a PyFlink Job
In this example we will:
- Upload our Python UDF and the program that calls it to Universal Blob Storage.
- Create a deployment that uses Ververica Platform's native PyFlink support to run our Python program in a PyFlink Job.
- Run the job and check the results.
First we save our Python UDF in a file my_udfs.py. Also, download the file pyflink_table_example.py from GitHub.
To run the Python code, we need to upload both files to Universal Blob Storage in a platform instance.
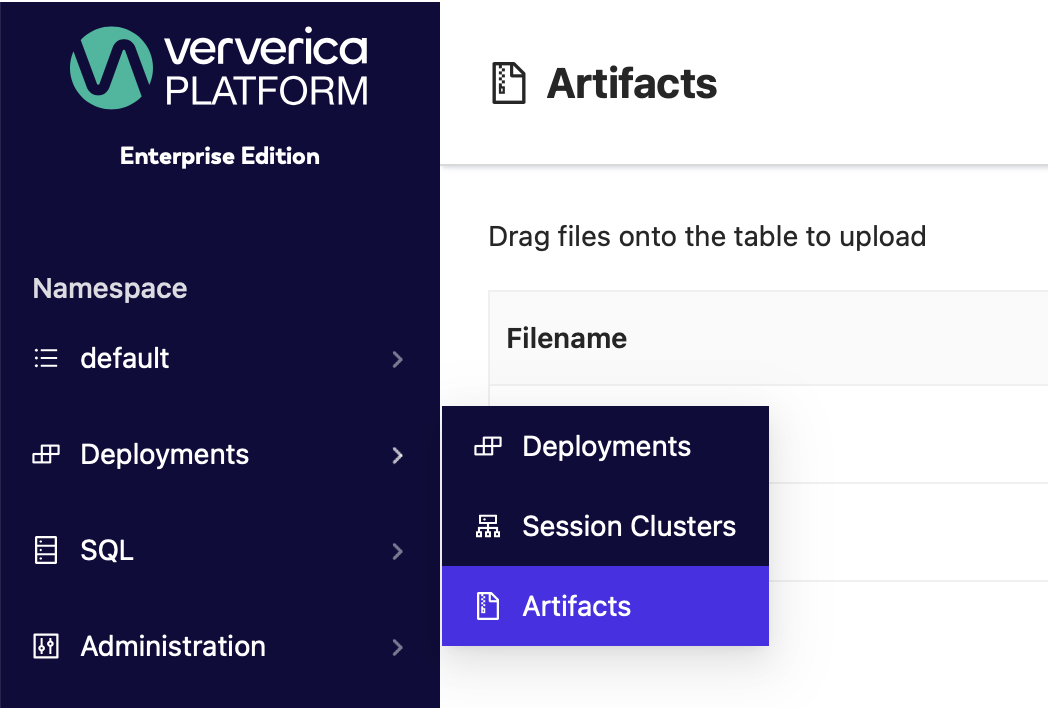
In your platform instance, select Deployments | Artifacts from the Deployments menu, and drag the files to upload them:
Next, create your deployment. There are minor configuration differences for Ververica Platform versions before 2.10, so use the appropriate example.
A deployment target should automatically load from the deployment configuration drop-down menu in Deployment Target. If you don't see a target, go to Administration | Deployment Targets. Click Add Deployment Target, create a target deployment name and a Kubernetes namespace, for example vvp-jobs.
Create your deployment with the following values:
- Ververica Platform 2.10 and later
- Ververica Platform 2.8/2.9
We specify the Python files we uploaded as Additional Dependencies.
| Property | Value |
|---|---|
| Python URI | pyflink_table_example.py |
| Additional Python Libraries | Select my_udfs.py in the dropdown menu |
| Flink registry | <your own container registry> |
| Flink repository | flink |
Before Ververica Platform 2.10 we must specify a PythonDriver to run
our job. We use the same driver PyFlink uses internally, for example
flink-python_2.12-1.15.2.jar. To use a different version, change
the two Flink versions in the Jar URI, and change the Flink Image
Tag to match the same version.
To use the built-in images from Ververica Platform, specify the Flink
registry for the version you are using, for example
registry.ververica.com/v2.9 to use the built-in images from
Ververica Platform 2.9. Alternatively, point to your own registry.
We specify the Python files we uploaded as Additional Dependencies.
| Property | Value |
|---|---|
| Jar URI | https://repo1.maven.org/maven2/org/apache/flink/flink-python_2.12/1.15.2/flink-python_2.12-1.15.2.jar |
| Additional Dependencies | Select both pyflink_table_example.py and my_udfs.py in the dropdown menu |
| Flink Version | Match to the version you specified in Jar URI |
| Flink Image Tag | 1.15.2-stream4-scala_2.12-java11-python3.8-pyflink |
| Flink registry | <your own container registry> |
| Flink repository | flink |
| Entrypoint Class | org.apache.flink.client.python.PythonDriver |
| Entrypoint main args | --python /flink/usrlib/pyflink_table_example.py --pyFiles /flink/usrlib/my_udfs.py |
When the Flink job starts, in this case our PyFlink job, Ververica Platform downloads the artifacts from its Universal Blob Storage to the user directory specified in the Entrypoint main args, here /flink/usrlib.
To run the PyFlink job, start this deployment. Because the job has a bounded data input, the deployment will end in the FINISHED state and the Flink pods will be torn down, but you should be able to find the following result in the logs of the jobmanager pod. The values in the city column have been uppercased as expected:
+----+----------------------+--------------------------------+
| op | id | city |
+----+----------------------+--------------------------------+
| +I | 1 | BERLIN |
| +I | 2 | SHANGHAI |
| +I | 3 | NEW YORK |
| +I | 4 | HANGZHOU |
+----+----------------------+--------------------------------+
For more about the deployment lifecycle and states, see Deployment Lifecycle.
Call Python UDFs in a Java Table API Job
In this example we:
- Call Python UDFs from a Java based Table API program.
- In our Java code, set the path to the Python file containing the UDF, and map the Python function so we can call it from Java.
- Add the Python file as a deployment dependency.
On Ververica Platform versions earlier than 2.10, we needed an extra step:
- Include Python Driver
flink-python_2.12as a dependency and package it into the job JAR file.
As well as calling Python UDFs from Python programs, you can also call them from Table API programs written in Java. This is useful when several teams collaborate on Python UDFs. For example, one team of domain experts may develop Python UDFs and provide them to a team of Java developers for use in their Table API jobs.
We will use the same Python example my_udfs.py, but this time with a Java job JavaTableExample.java which you can download here.
To make this work we need to do a few extra things.
First, we need to tell JavaTableExample.java to load the example
UDF, which we do by calling .setString to set the value of PyFlink
python.files configuration property. Remember, /flink/usrlib
is the directory to which Ververica Platform downloads artifacts when
it starts a Flink job:
tableEnv.getConfig().getConfiguration()
.setString("python.files", "/flink/usrlib/my_udfs.py");
We create a temporary mapping for the Python function by calling executeSql() to map the Python function to a Flink SQL system variable PY_UPPER:
tableEnv.executeSql("create temporary system function PY_UPPER as
'my_udfs.py_upper' language python");
Now we can use the function PY_UPPER in our SQL SELECT statement:
tableEnv.sqlQuery(
"SELECT user, PY_UPPER(product), amount FROM " + table)
As before, to run the job we need to upload my_udfs.py to our platform instance Universal Blob Storage. You can skip this if you already did so.
Finally, package the job as a JAR file:
- Ververica Platform 2.10 and later
- Ververica Platform 2.8/2.9
To create the example JAR file, download pom.xml, available
here.
Remove the PythonDriver dependency block, which is not needed:
<!-- Flink's PythonDriver -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-python_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
Run mvn clean package. This creates
JavaTableExample-1.0-SNAPSHOT.jar under the directory target.
To create the example JAR file, download pom.xml, available
here.
The file includes a PythonDriver dependency block, which we need for these versions of Ververica Platform:
<!-- Flink's PythonDriver -->
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-python_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
<scope>compile</scope>
</dependency>
If you change the Flink version, make sure you specify the same version throughout the configuration.
Run mvn clean package. This creates
JavaTableExample-1.0-SNAPSHOT.jar under the directory target.
Now create a deployment:
- Ververica Platform 2.10 and later
- Ververica Platform 2.8/2.9
With the following difference, this is like a standard JAR deployment:
- Add
my_udfs.pyunder Additional Dependencies in the deployment configuration.
With the following differences, this is like a standard JAR deployment:
- Add
my_udfs.pyunder Additional Dependencies in the deployment configuration. - Specify
1.15.2-stream4-scala_2.12-java11-python3.8-pyflink(or the appropriate PyFlink image you prefer) under Flink Image Tag in the deployment configuration — ensure your PyFlink versioning is consistent.
Start the deployment. The Python UDF will be called during the job run. As with the pure Python example, because the job has a bounded data input, the deployment will end in the FINISHED state with the Flink pods torn down. Again, check the jobmanager pod logs. The values in the product column have been uppercased as expected:
+----+----------------------+--------------------------------+-------------+
| op | user | product | amount |
+----+----------------------+--------------------------------+-------------+
| +I | 1 | BEER | 3 |
| +I | 2 | APPLE | 4 |
+----+----------------------+--------------------------------+-------------+
Building a Platform Image
If you are using older versions of Ververica Platform (earlier than 2.10), then depending on the combination of platform version and Flink version, PyFlink and Python may not be included in the standard platform images.
Ververica Platform 2.10 with Flink 1.15.3 or later
- PyFlink and a Python interpreter are included in the image.
- You do not need to build a custom image: you can just deploy a standard platform image from the Ververica registry.
Ververica Platform 2.8 or later with Flink 1.13/1.14
- For both 2.8 and 2.9 Ververica Platform versions with Flink 1.13 or 1.14, PyFlink and a Python interpreter are not included in the standard image.
- You need to create a custom Docker image to include the PyFlink and Python packages, and then build and deploy the image as shown below.
Build and push a custom Ververica Platform image
In your terminal, create a new directory and cd into it. This is where you will build the new image.
Build the image
Create a new file named Dockerfile with the following content:
FROM registry.ververica.com/v2.8/flink:1.15.2-stream4-scala_2.12-java11
USER root:root
RUN apt update \
&& apt -y install python3.8 python3-pip \
&& python3.8 -m pip install apache-flink==1.15.2 \
&& apt clean \
&& ln -s /usr/bin/python3.8 /usr/bin/python \
&& rm -rf /var/lib/apt/lists/*
USER flink:flink
In this example, the base image we use for the Dockerfile is the Flink 1.15.2 image for Ververica Platform v2.8, provided by the Ververica public registry.
Now build the Docker image:
docker build -t <your container registry>/flink:1.15.2-stream4-scala_2.12-java11-python3.8-pyflink
where the trailing . is the directory where Docker will look for a file named Dockerfile (or another name if you override with the -f option).
The image will be built in the context of this directory i.e. any host or relative paths in the Dockerfile will start from this directory. The image will be saved to the local Docker repository.
Push the image
Push the image to the container registry named by the tag -t option you built with. Make sure the registry you choose is reachable by Ververica Platform:
docker push <your container registry>/flink:1.15.2-stream4-scala_2.12-java11-python3.8-pyflink