Overview
If the origin and history of data are untraceable, it compromises data quality and security, leading to inefficient data analysis and troubleshooting. To mitigate this, fully managed Flink offers a feature to view data lineage. This lineage illustrates the relationships formed during data generation, processing, transmission, and consumption. It outlines the flow and dependencies among metadata and highlights the ties between metadata and both streaming and batch deployments. Understanding data lineage gives you a comprehensive insight into your data's journey. It also equips you with vital information for metadata management, data analysis, governance, and strategic decision-making. The following table describes the benefits of data lineage.
| Benefit | Description |
|---|---|
| Improved data verification efficiency | Data lineage tracks deployment-involved data sources sucha as products, databases, and tables. It reveals the data's origin and its utilization process, ensuring credibility and accuracy. Moreover, it provides insights into the properties and relationships of table fields. |
| Enhanced troubleshooting efficiency | In the event of data processing errors, data lineage can pinpoint the root cause, facilitating swift resolution, preventing business losses, and minimizing labor costs. |
| Boosted data analysis efficiency | Changes or errors in data assets can be addressed promptly by identifying affected online deployments using the data lineage, preventing inaccurate decisions. |
| Reduced data asset costs | Understanding data paths and dependencies via data lineage enables data processing optimization. It aids in decommissioning unused services, enhancing data processing quality, and consequently decreasing costs. |
Data lineage model
The following figure shows the model of data lineage.
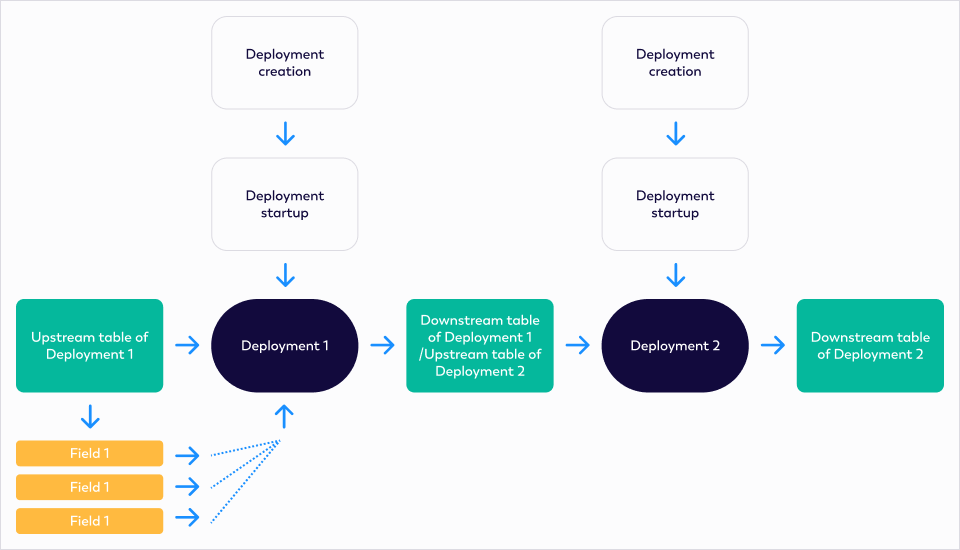
The diagram above contains nodes (entities) and edges (relationships). The combination of entities and relationships is displayed as data lineage.
| Item | Description |
|---|---|
| Node | In data lineage, every catalog, data table, and field is represented as a data entity. These entities are visualized as nodes. The types of nodes in data lineage include:
|
| Relationship | Entities have relationships with both their upstream producers and downstream consumers. In data lineage, the key relationships are:
|
Limits
- To see data lineage from the metadata perspective, you must use a catalog. However, to see it from the deployment perspective, you don't need a catalog.
- You can view and search data lineage for SQL deployments only.
- You must start an SQL deployment at least once to view its data lineage. After you cancel the deployment, it retains the most recent data lineage.